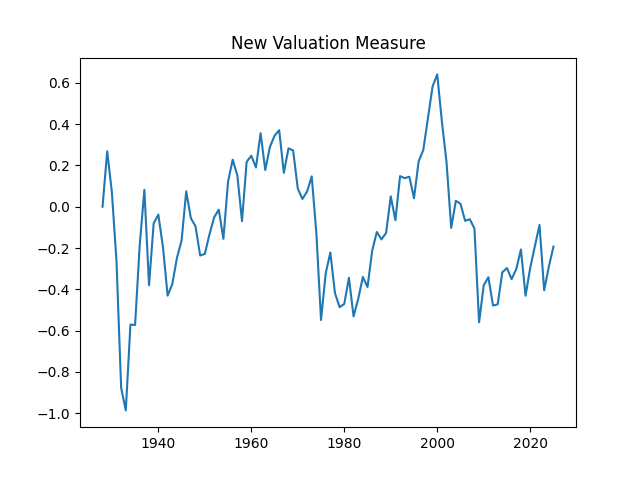
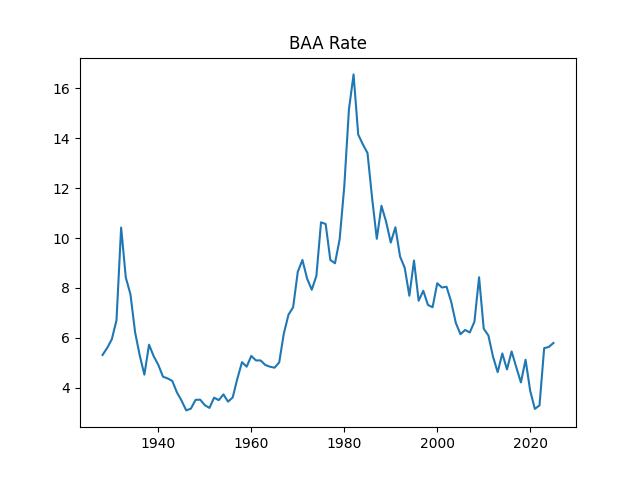
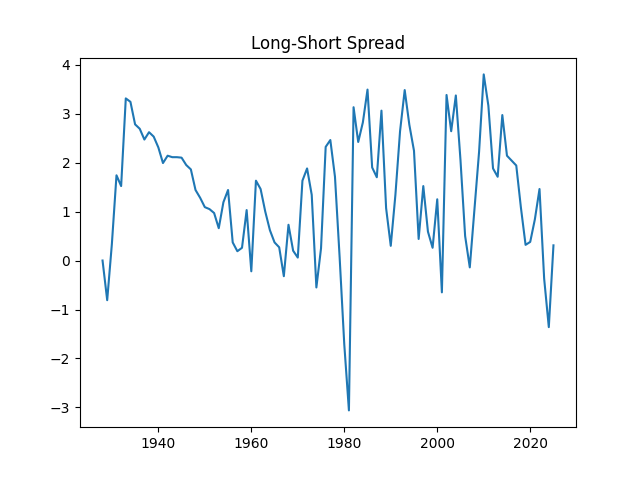
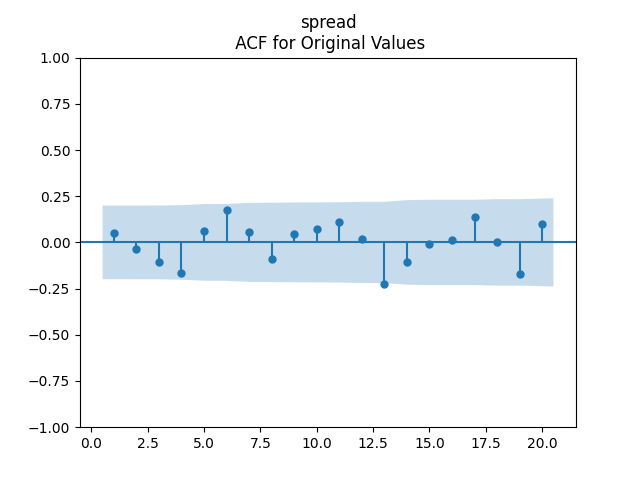
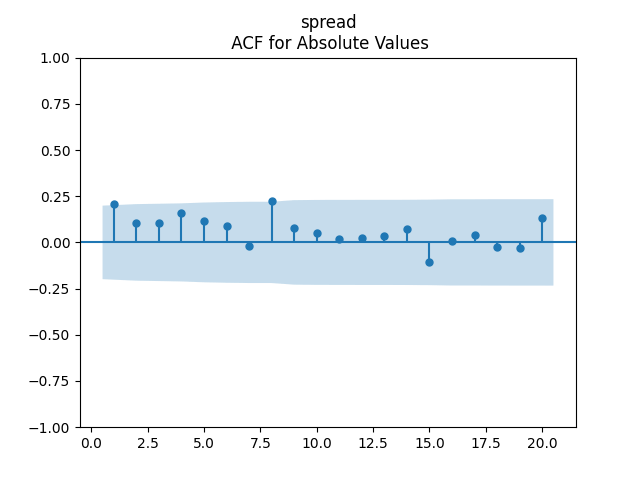
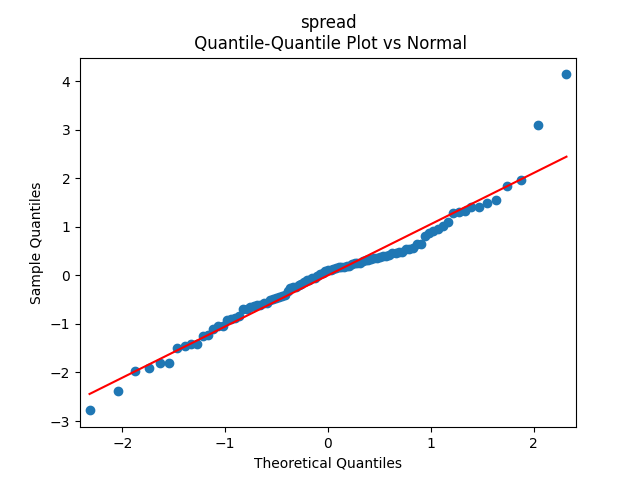
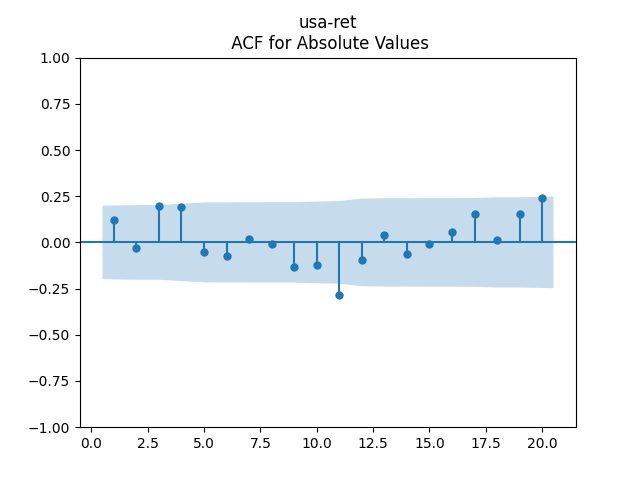
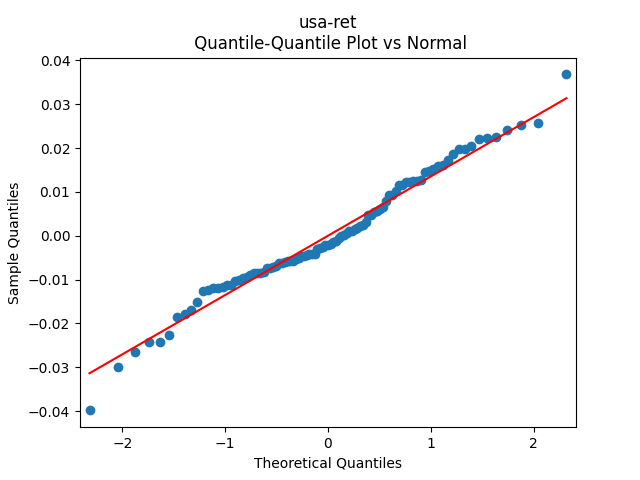
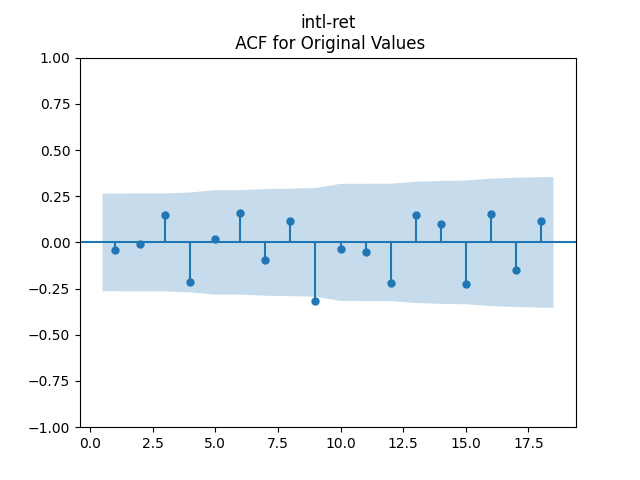
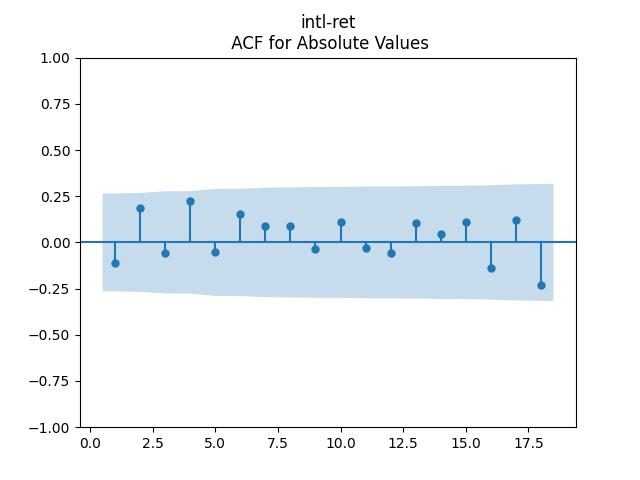
Consider the new valuation measure which is supposed to be an improvement of Shiller CAPE and dividend yield. Previously, we considered this measure based on trailing 10-year earnings. Right now, we consider it based on 1-year dividend yield and use it to create a new simulator. But recently, it occurred to me that one can express this measure based on the history of annual dividend yields. How so? Let us recall that the valuation measure is defined as
where is the wealth at end of year invested in stocks, and is dividend paid in year for these stocks. And is the linear trend. Assume now is end-of-year level at year Then is the dividend yield for this year. Total returns then are and we can express
The crucial insight:
Plugging this into the main formula for and denoting we get:
Canceling these logarithms, we get
which we can write as which in turn, finally, we can write as
If is a strongly stationary process such that satisfies the Strong Law of Large Numbers (ergodic), then this measure converges to the stationary distribution if and only if is the mean of this
Well-diversified stock portfolios are well-explained by three factors:
market exposure to the equity premium (total returns minus risk-free returns)
size (market capitalization) computed as returns of small minus returns of large stocks
value (measured by book-to-market ratio) computed as returns of stocks with high minus low ratio
The is usually very high. Of course, such factors might be not constant over time. For example, the is famously unstable. To model properly such portfolios, we must model also the evolution of these factors, by showing how the size and value are changing. I am working on this based on
The market exposure is already modeled since equity premium divided by annual volatility is independent identically distributed Gaussian. Thus I decided to model returns of size and value factors. I took annual returns 1927-2025 from Dartmouth College data library. See the GitHub repository.
We succeeded for value but failed for size. We cannot use this in our future research!
I wish to include the risk spreads BAA-AAA or BAA-Long as factors for stock returns, continuing this research. We use the valuation measure based on one-year dividends not ten-year earnings. Also, maybe bond returns, continuing this blog post.
Maybe these risk spreads will improve our prediction. But we need to ensure that innovations and residuals are independent identically distributed and Gaussian.
Also, the term spread Long-Short might be useful. But it does not fit our Gaussian assumptions for innovations.
Finally, include Long in our model, since this will allow us to model long-term Treasury returns. Indeed, Long corresponds to 10-year yields but with coupons. This makes it difficult to compute returns explicitly. However, we have 10-year and 9-year zero-coupon bonds which have yields very close to these 10-year coupons. See the Federal Reserve Economic Data. Indeed, let be the end-of-year (December daily average, more precisely) rate (assuming these three rates are the same). Then the price of a 10-year zero-coupon bond at end of year is and it becomes a 9-year zero-coupon bond with rate by end of year with price and the geometric returns are
We can compute returns for zero-coupon bonds, because we compute its price explicitly. A big difficulty from this post is that Long rates do not have residuals which are independent identically distributed and Gaussian.
Note that, unfortunately, in our previous research we used the long rates which are time-inconsistent: DGS10 are taken to be end-of-year, but LTGOV which precede DGS10 are December monthly average. Only in a recent post we correct this, taking both to be monthly average, when we unsuccessfully fit autoregression for long-short bond spread (with and without volatility).
The Python file and data.xlsx in the same GitHub repository shows that we tried to fit Long separately, with and without volatility, and failed. We also tried with (BAA, Long) with and without volatility as vector autoregression, and failed. Finally, we tried the BAA-Long spread, and also did not succeed.
Further tries to switch to log rates instead of rates failed for the Long and combined model. Except one: If we take log of spread, then this fits autoregression without volatility normalization. Together with the model for the BAA rate, this gives us the right model. In fact, we succeeded in our modeling: For and we model and for Gaussian independent identically distributed
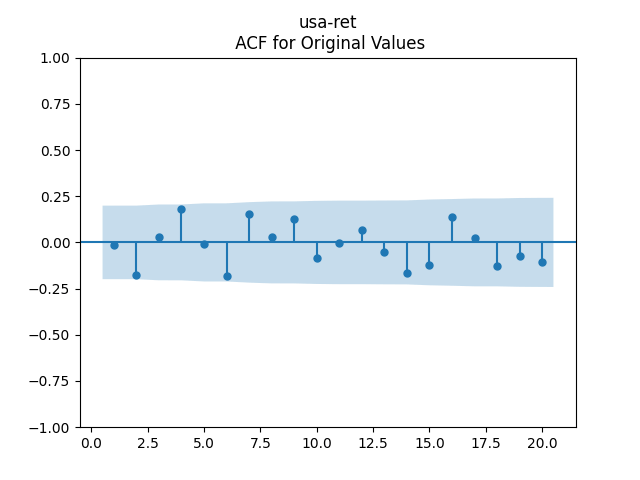
Finally, we consider regression of US stock normalized returns upon the spreads. We try 12 versions, with various combinations of volatility, 6 with original spreads and 6 with log spreads. But we could accept only two versions out of these 12: with standing for either the spread or the log spread. We prefer the model with the log spread because the p-values for the Ljung-Box test are further from 0.05.
This implies we should use this regression of log spreads divided by volatility as a factor in our further models. See the same GitHub repository.
Valuation measure. Continuing the previous post, let us include the valuation measure based on one-year dividend, described in previous posts: The regression which defines such measure is an autoregression of order 1 with a linear trend: Its innovations do not satisfy the assumptions 1-5 from the previous post. Therefore, we reject the regression as the model. But we accept this model:
The values are The is significantly different from one. There is no unit root.
Historical factors. The latest (as of 2025) and long-term average of these three factors are:
The volatility is 11.77 and 10.51
The BAA rate is 5.9 and 6.8
The new valuation measure is 0.192 and 0.24
Domestic returns. Now add the new valuation measure as a factor for domestic returns. We accept this model: The values are All coefficients are significantly different from zero. Also, which is very high! Usually, annual stock returns are not very predictable.
International returns. Add the new valuation measure for international returns, although they are made for domestic returns. The regression model is accepted, and and all coefficients are significant except the valuation measure. So it is not needed, after all. Without the new valuation measure, the regression has We do not need this!
Covariance and correlation. In order and we can treat them as multivariate Gaussian independent identically distributed with covariance matrix (times 10000):
1. Methodology. In my previous post, I relied on ACF and QQ plots to choose whether innovations are IID Gaussian. But I thought this is too informal. Let me instead select the model based on the following. Each series of residuals must have for each of the following 5 statistical tests:
The Jarque-Bera normality test for original values of residuals
The Ljung-Box white noise test for original values of residuals with 5 lags
The Ljung-Box white noise test for original values of residuals with 10 lags
The Ljung-Box white noise test for absolute values of residuals with 5 lags
The Ljung-Box white noise test for absolute values of residuals with 10 lags
2. Results. We accept the following models:
Stock Returns: is modeled as for which corresponds to domestic and international geometric stock returns. Also, a sub-model with (no duration) or (no volatility as an additive factor) or both.
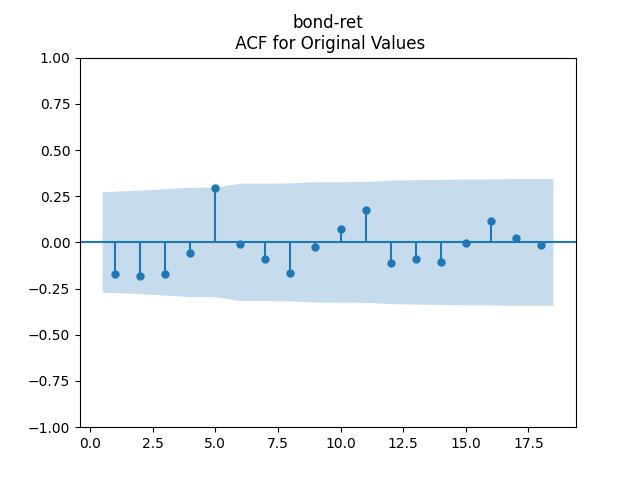
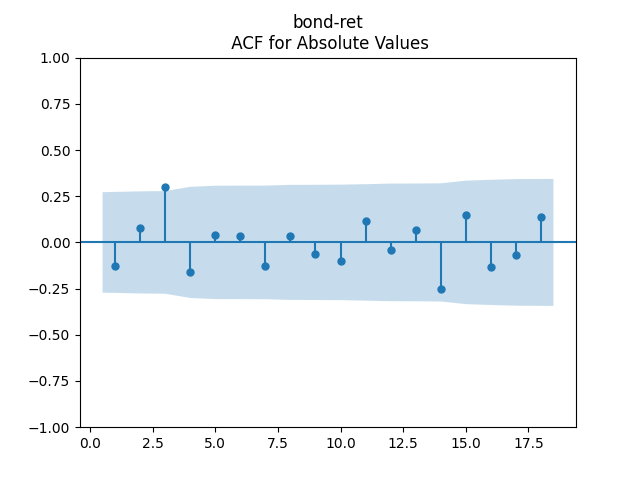
Bond Returns: Continue this blog post. Adjust them and regress or We accept them but reject the augmented models (for both arithmetic and geometric adjusted returns): with factors (intercept) and (volatility as an additive factor).
Volatility: The classic AR(1) model for log volatility works.
Bond Rates: Consider autoregression with volatility is accepted. But we reject the one with instead of or with Models with instead of are rejected. These are stationary models.
Random walk for logarithms is also accepted, as well as an augmented model with volatility as an additive factor: The models without logarithms or volatility or both are rejected. These are non-stationary models.
3. Choice. We pick the following model: for and for stock and bond returns. Next, AR(1) for log volatility and for log rates.
Stock Returns: for domestic and for international stocks.
Bond Returns:
Stock Volatility:
Bond Rates:
The covariance matrix for innovations (times 10000) is:
This post focuses on models having innovations which are not only independent identically distributed (IID) but Gaussian. It is clear why this makes them so easy to analyze and simulate.
Model building goals. We evaluate the model based on innovations.
Is each series of innovations a (weak) white noise, measured by the empirical autocorrelation function (ACF) and standard Ljung-Box white noise tests? If yes, this would mean autocorrelations are zero. But this does not yet mean the series is truly IID. Stochastic volatility models show why.
Is each series of innovations after taking their absolute values have autotocorrelations zero? We again apply the empirical ACF and the Ljung-Box white noise tests. If yes, and the first answer above is also yes, then it is reasonable to model this series as IID.
Is each series of innovations Gaussian? We can ask this question only if we answered affirmatively on the first two. This is answered by making a quantile-quantile plot versus the normal distribution and applying Jarque-Bera normality test.
As an attentive reader can see, the techniques are essentially the same as previously. But there are a couple of important differences.
First, we apply the Ljung-Box white noise tests based on the (weighted) sum of squares, not the customized sum of absolute values tests we considered previously. I think it is simply easier and better known to apply Ljung-Box tests. The test based on L1 norm did not really show anything special different from L2 tests.
Second, we do not apply the Shapiro-Wilk normality test. We consider it to be a bit of an overkill. Jarque-Bera test captures skewness and fat tails commonly present in financial analysis which prevent the data from being normal. And anyway, the Jarque-Bera test is present in the standard Python OLS regression output.
Let us stress what features we are not interested in.
Maximizing of linear regressions
Information criteria (Akakie/Bayesian)
Minimizing the standard error of regression residuals.
Data description. We have annual data 1927-2025. It is available as a spreadsheet here. Take five data series:
Total returns invested in S&P 500 and its predecessor, S&P 90: during year available 1928-2025. End-of-year values were taken by Ian Anderson from Yahoo Finance, and dividend annual data is taken from Robert Shiller’s data library. See the source here.
Total returns for international stocks (see remark below): available 1970-2025.
Total return index value for the USA corporate bonds (measured by Bank of America Intercontinental Exchange total return index value, taken from Federal Reserve Economic Data (FRED) web site), available 1972-2025.
December daily average BAA Moody’s rate: available for 1927-2025 also from FRED web site.
A note on international stocks. The total returns of international stocks are now measured by a customized portfolio of 88% MSCI EAFE and 12% MSCI Canada. I did this adjustment because the data for MSCI EAFE (=developed markets including Europe, Australia and Far East) was available from 1970 on the web site Novel Investor, as opposed to MSCI emerging markets (available only from 1988), but this EAFE index did not include Canada! I thought this is very unfair, since Canada is a major component (~12%) of existing developed market stock ETFs. So I decided to include it manually. The data for Canada was also available as another MSCI index from 1970.
The simplest model equations. Try modeling where are innovation series. This is in line with our long-standing idea of dividing stock returns by volatility to make them closer to IID Gaussian. It works perfectly well here.
Also, Note that this makes the rates non-stationary: More like a geometric random walk, except we have stochastic volatility here. This is one more remarkable example of how to use stock volatility for bonds, which we discussed earlier.
Next, the equation for volatility stays the same as in Angel Piotrowski’s analysis:
Finally, the equation for bond returns is as follows:
Each is IID Gaussian series with mean zero. This is confirmed by the tests and graphs above.
Properties of this model. As mentioned above, rates and therefore bond returns are non-stationary. But stock returns and volatility are stationary. Also, stock returns do not have duration in their modeling. In fact, if we include the same difference term, it would be highly significant, with extremely high T-value. But we decided to create the simplest model.
Extensions. We can increase complexity of this model as follows:
Include then the innovations are also IID Gaussian. This involves duration for stocks just like for bonds. The values of coefficients are significantly different from zero. Accept!
Include a constant for increments of log rates and has for Student T-test. Accept!
On top of item 1, for stock returns (both domestic and international) we can add volatility as an additive factor, not just multiplicative: Here is different from zero, judging by the Student T-test. Accept!
We could run the autoregression with stochastic volatility terms but this violates normality of Same would be true for the simple autoregression Reject! Unfortunately, this means we must consider a non-stationary model.
We could add volatility to bond returns as an additive factor, not just a multiplicative one. Thus we make regression But this would fail the IID assumption. Reject!
Writing we replace de facto arithmetic returns with geometric returns, but in a modified way. The IID Gaussian assumption holds. Accept!
Adding volatility to bond returns as an additive factor, not just a multiplicative one: Similarly to 5, but with model as in 6, then the IID fails. Reject!
The new valuation measure. Following previous blog posts, we consider comparing total annual returns with annual dividend growth and detrending it. Take cumulative quantities, which can be expressed using current dividends: and regress versus the previous value and the time trend We get: [/latex] M(t+1) – M(t) = \alpha + \beta M(t) + \gamma t + W(t). [/latex] Similarly to the article we rewrite this as a simple autoregression for detrended This autoregression will also have residuals Such residuals are tested and they do not pass our tests: They are not IID. Reject!
The long-short term spread. We considered this spread between 10-year and 3-month average December annual rates, and its predecessors from 1927.
Classic autoregression:
AR with stochastic volatility:
AR with stochastic volatility but without volatility as an additive factor:
Unfortunately, none has Gaussian residuals. Reject!
1. Introduction and data description. Continue the research after updating the data for 2025. In the previous post, we discussed total returns for S&P 500 in detail. Now we discuss bond returns. We take the same data as above, and for bond wealth process , we take FRED series BAMLCC0A0CMTRIV, last trading day of year 1972-2025. We start from for the last trading day of 1972, and go on from there. This way we can compute log price returns for year
2. Relation between price returns and wealth process. We derive log price returns from this wealth process using bond math. Then we run linear regression of this log price returns versus rate change. This regression coefficient is called the duration. In continuous setting, this is defined as minus derivative of the log price with respect to the interest rate. More precisely, we use yield to maturity as this interest rate.
Wealth at end of year is and at end of year is Assuming the price of this bond at end of year is Then the coupon paid during year is The wealth at end of year is the sum of this coupon and the price at end of year Combining this, we get:
We have This gives us the formula for log price returns:
Since are observed, we can compute If we fit this model, we can rewrite
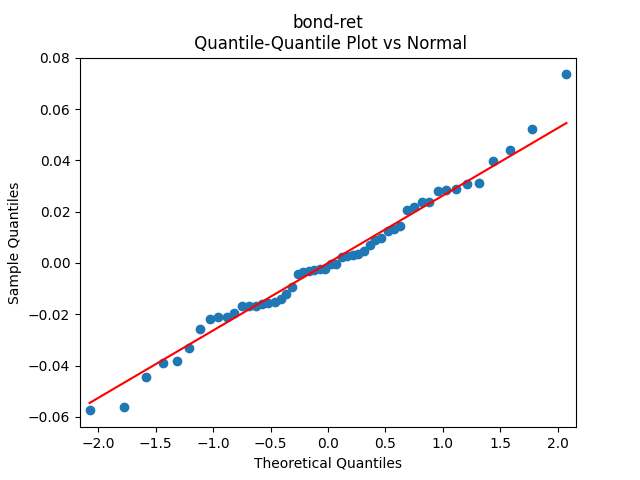
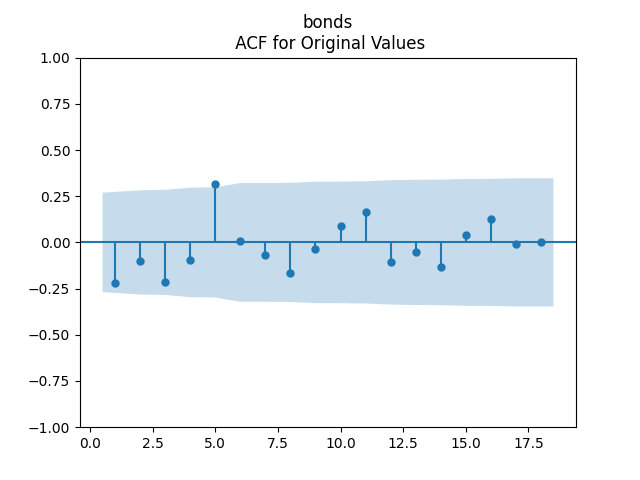
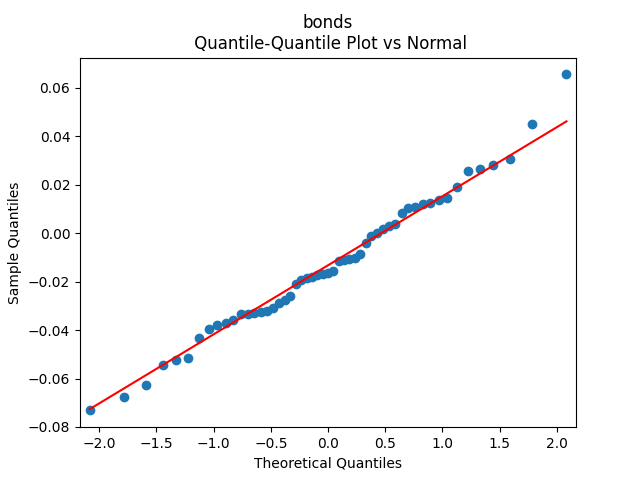
3. Fitting linear regression. As mentioned above, the log price returns can be regressed upon We do not include an intercept into this regression, since this has the meaning of a discrete approximation of a derivative. The regression coefficient is 6.1053, and the residual analysis is done by the plots below. These are Gaussian but not quite independent identically distributed. This is confirmed by the p-values of Shapiro-Wilk and Jarque-Bera normality tests: and And by the Ljung-Box test for 5 lags for original and absolute values of residuals, which give us and
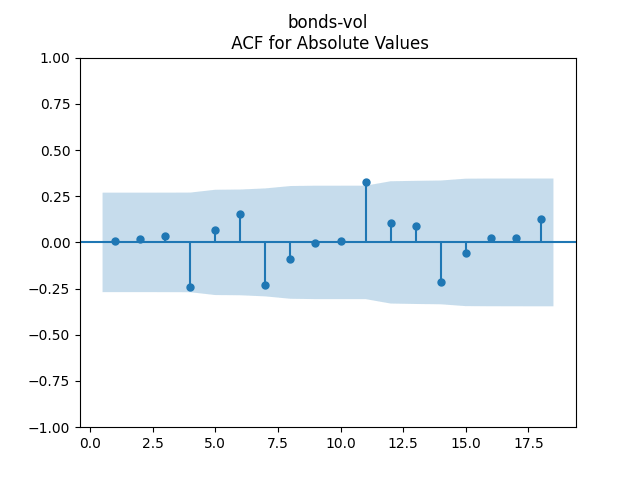
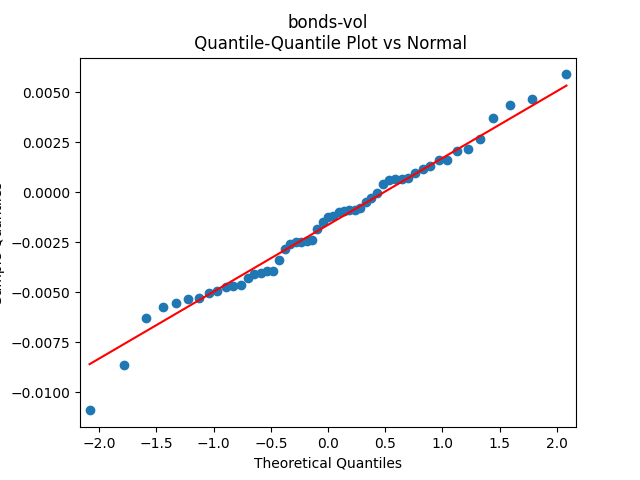
To make residuals independent identically distributed, we divide each term by annual volatility This is equivalent to assuming that the residuals are heteroscedastic: These are white noise multiplied by This gives us 5.96 regression coefficient, and for Shapiro-Wilk normality test, for Jarque-Bera normality test. Also, the Ljung-Box test for the first 5 lags of original residuals has and for absolute residuals has Finally, see the graphs for residuals below.
4. Conclusion. We have where are independent identically distributed Gaussian. We succeeded in modeling the bond market! Duration in both cases is around What is more, this is better than previous models:
We clearly explain the meaning of duration as dependence measure of the price upon yield to maturity, and not rely on approximate formulas, such as in this blog post
We used volatility in our model, but stock volatility used for bond returns is highly unusual
Residuals are independent identically distributed and Gaussian
Together with the two previous blog posts, we can now create a complete model of:
BAA rates
Dividends
The volatility
The valuation measure
Total stock returns
Total bond returns
These are 6 time series with 5 innovation sequences. Thus we can use it to create a simpler version of the financial simulator.
1. Motivation of the new valuation measure. We continue the previous blog post. We replicate the valuation measure here. We use updated data for 2025. Previously we did this with 10-year earnings but now we wish to do this with 1-year dividends.
We prefer dividends to earnings for the following reasons:
Dividends are the actual cash paid, and they are not disputable, but earnings depend on accounting standards
Dividends are more predictable, since companies do not like to cut them, but earnings are highly volatile
Earnings of companies can be negative, and thus suffer from the aggregation bias, but dividends are nonnegative
2. Fit autoregression with linear trend as before: Take the index level at end of year and dividends paid at year Total returns and dividend growth are given by and
We model the cumulative difference as a simple autoregression of order 1 with trend: where are innovations. The valuation measure then is defined as
This can be written as We fit The autoregression becomes the random walk (there is no mean-reversion) if but this hypothesis has which is very low. Next, the trend coefficient is zero if which has
From here, we can deduce and compute the valuation measure The measure, as before, shows us that the market is not overvalued, since it is average compared to the historical standard.
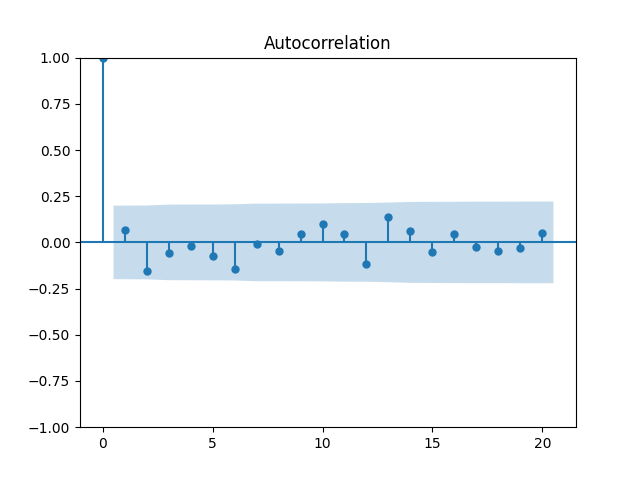
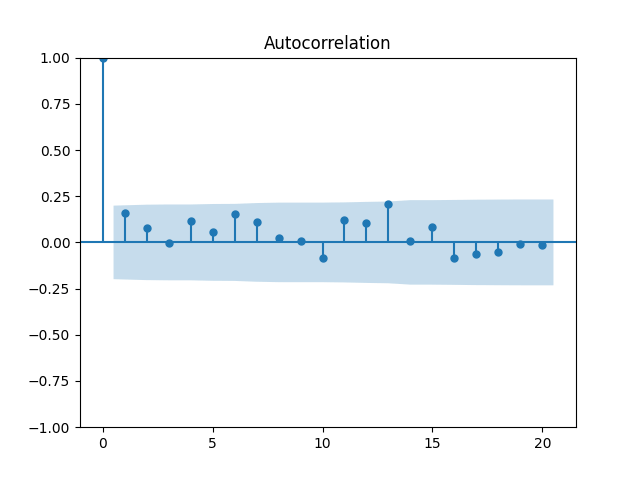
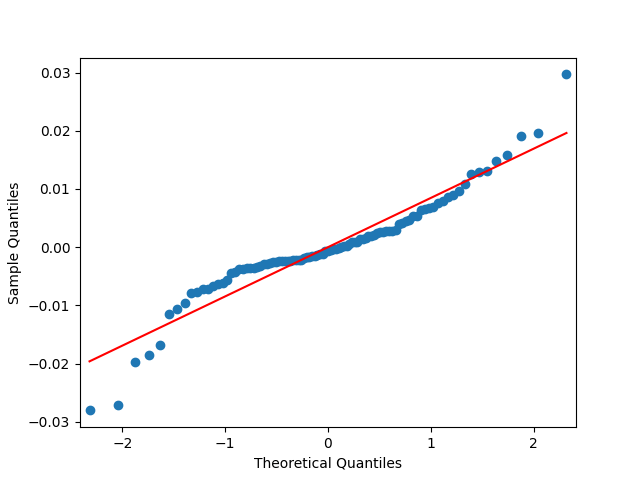
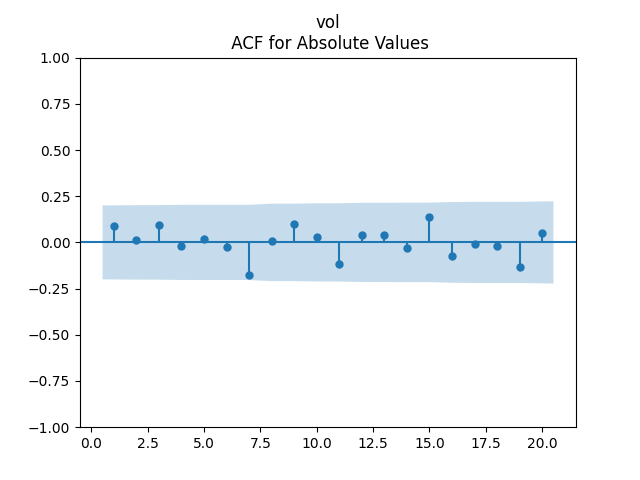
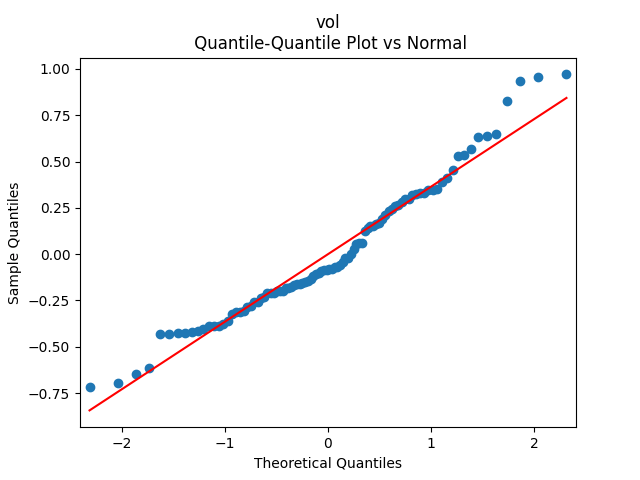
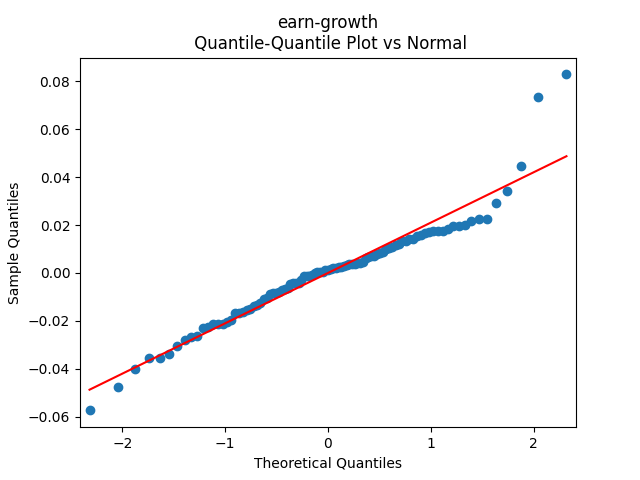
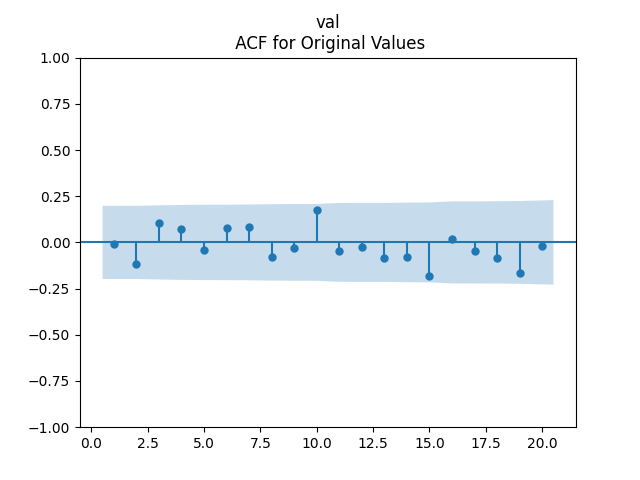
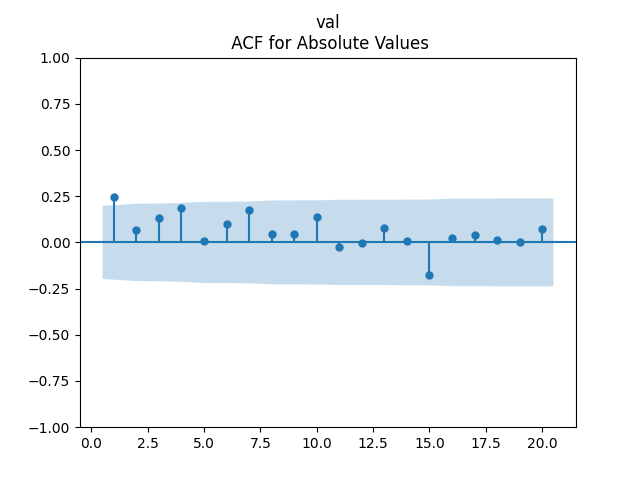
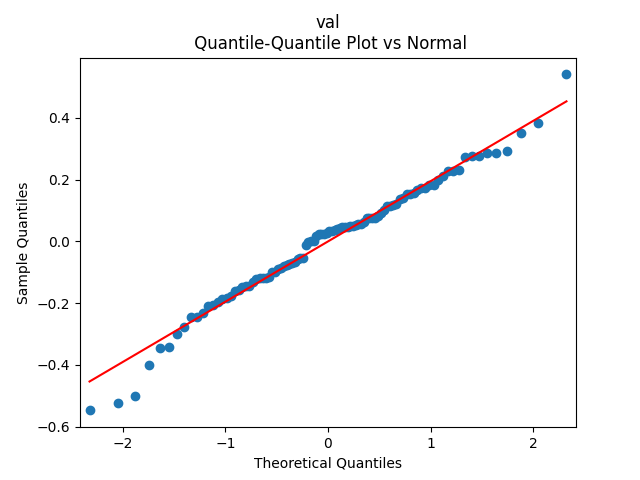
Analysis of residuals: See the autocorrelation function plots for and for as well as the quantile-quantile plot for The Shapiro-Wilk and the Jarque-Bera test give us and
We can approximately assume that residuals are independent identically distributed Gaussian, although the autocorrelation function for lag 1 for the absolute values of innovations raises questions.
3. Use this valuation measure for modeling returns. We can model total stock returns with dividends.
Model 1. Since we know how to model dividend growth from the previous blog post, together with annual volatility, we can simply model stock returns using three time series:
the new valuation measure as autoregression
volatility as another autoregression on the log scale
normalized dividend growth as yet another autoregression
Model 2. However, we can also regress upon as follows:
We get Also the p-value for hypothesis is The plots for residuals are below. This is independent identically distributed but not normal. Same is confirmed by the two normality tests, which give us extremely low p-values.
This model uses four time series, but with only three series of innovations:
returns regressed upon last year’s new valuation measure
the new valuation measure as the detrended difference of total returns and dividend growth
volatility as another autoregression on the log scale
normalized dividend growth as yet another autoregression
The second time series is without new innovations: Indeed, we simply write from the definition of the new valuation measure; and this does not have any new innovations. We modeled and separately.
Model 3. Let us modify Model 2 to include division by volatility: We divide by both returns and the right-hand side.
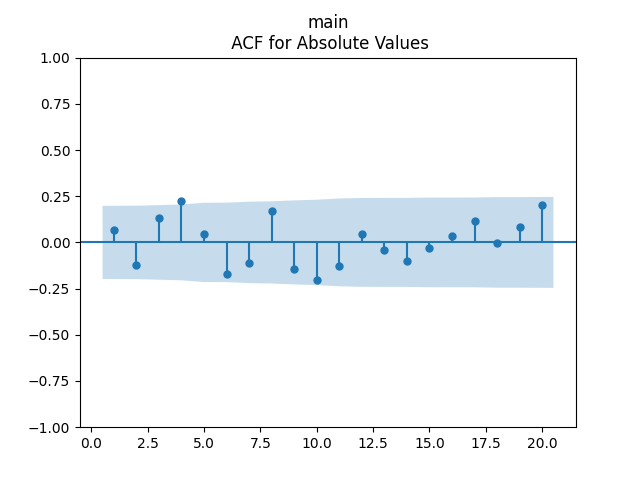
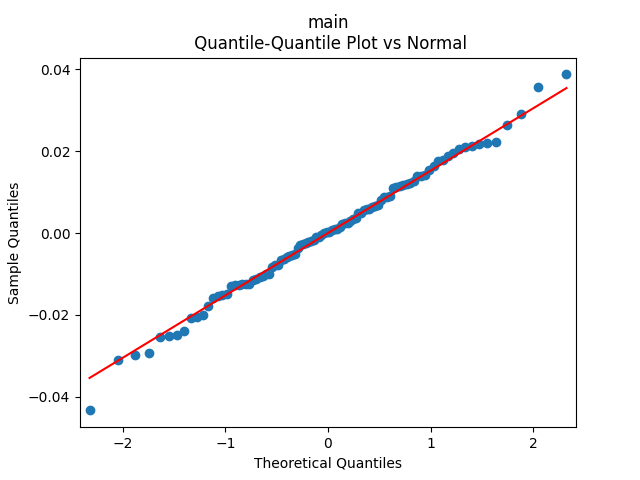
We get The p-values are all or less. The normality tests for innovations show p-values above 90% and this is confirmed by the plot below. The values of can be modeled as independent identically distributed Gaussian, therefore; see the three plots below.
This model also uses four time series but with three series of innovations, as in Model 2.
4. Include bond rates and duration. Following the previous blog post, we include rate change in our time series models. Here is the BAA rate, December daily average for year
Model 1. Try to include this rate change as a factor in dividend growth model The two other time series: the valuation measure and the volatility do not need rate change as the factor. We get:
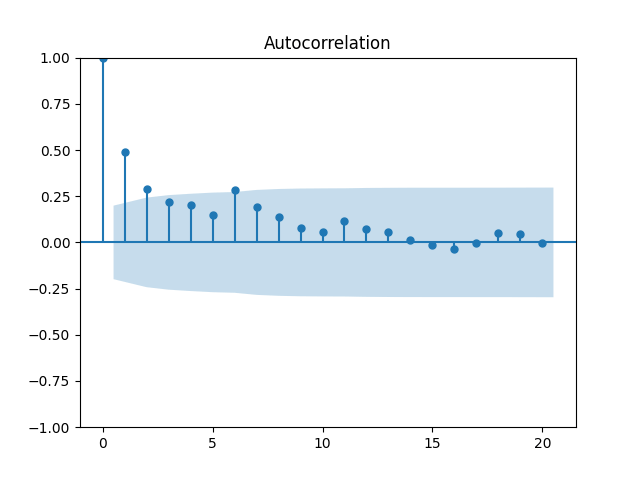
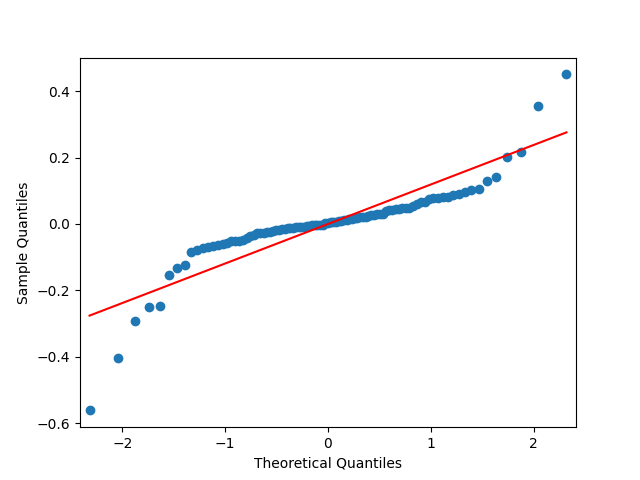
But we run into problems: The coefficient is not significantly different from zero, with and the autocorrelation function and quantile-quantile plots for residuals shows this is not independent identically distributed and not Gaussian, see below.
Similar results are if is divided by Thus we abandon this idea of including duration (dependence upon rate change) in normalized log dividend growth.
Finally, try to include instead of This means using rate itself instead of rate change as a factor. Or normalize this rate by volatility: In each case, still we have these plots as above for regression residuals.
Conclusion: We failed to model normalized dividend growth using rate or rate change for BAA bonds.
Model 2. Include duration in the regression for total returns, together with the valuation measure:
We get with p-values 8.6% for valuation coefficient zero and less than 0.1% for intercept and duration. Also, the residuals are Gaussian, with Shapiro-Wilk and Jarque-Bera normality tests giving us and But not independent identically distributed. See the three graphs below.
Conclusion: We failed to include duration in total returns modeling without normalizing by volatility.
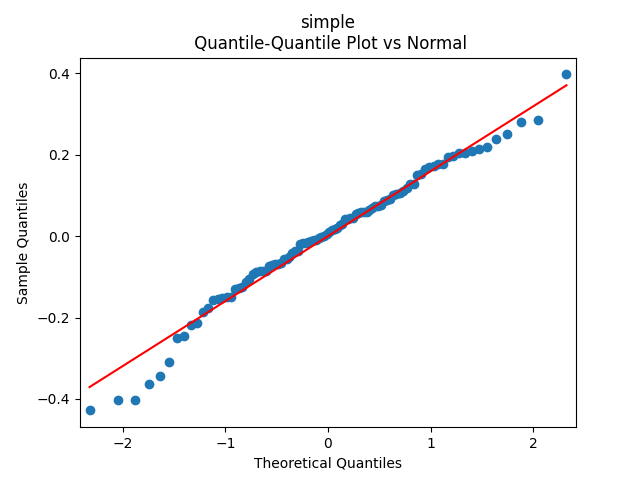
Model 3. Include duration in the regression for total returns, together with the valuation measure:
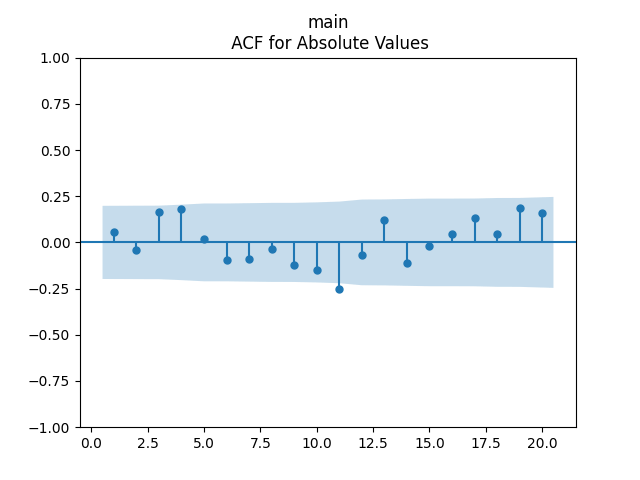
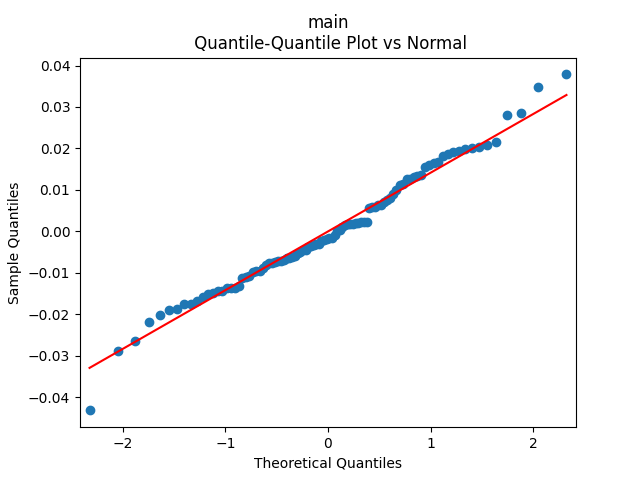
We get a much better fit than without the duration or in Model 2: with p-values 0.4% for valuation coefficient zero and 0.1% or less for others. Also, the residuals are Gaussian, with Shapiro-Wilk and Jarque-Bera normality tests giving us and Finally, looking at autocorrelation function plots for and for we see that residuals are independent identically distributed Gaussian.
Conclusion: Here we succeeded in including the duration as a factor for regression modeling of total returns after normalizing.
5. Conclusion: We can reasonably model the new valuation measure using one-year dividends, not trailing ten- or five-year earnings, as in previous articles or blog posts. This might be better, since in previous models we used both dividends and earnings, but here we use only dividends. It is useful to include rate change as a factor in a regression for total returns, but only after normalizing, and not for normalized dividend growth. This updates our blog post. In the next post, we consider total corporate bond returns modeling using bond rates.
Dear readers, after a long break, I am back. I updated the annual volatility and other data for S&P 500 for the year 2025. The data are available here.
Data Updates
New Graphs
Total Returns
Volatility Autoregression
Price Returns
BAA Bond Rates
Dividend Growth
Conclusion
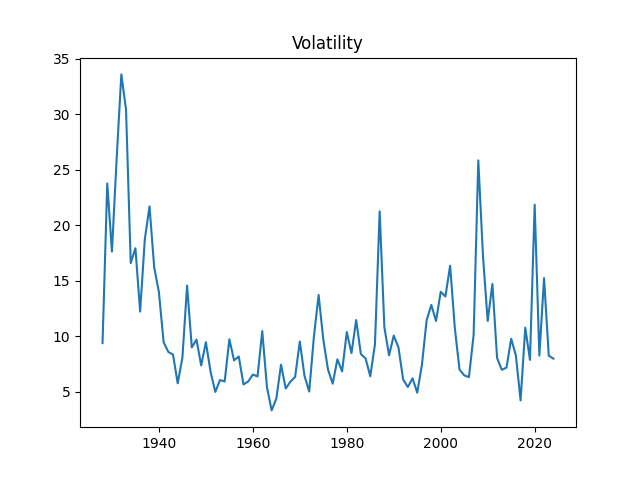
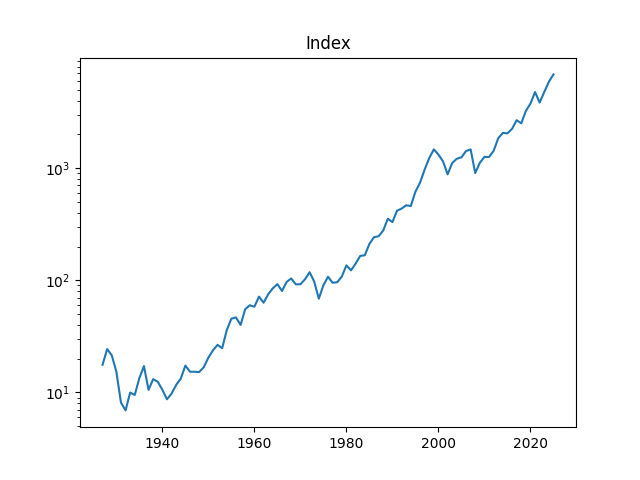
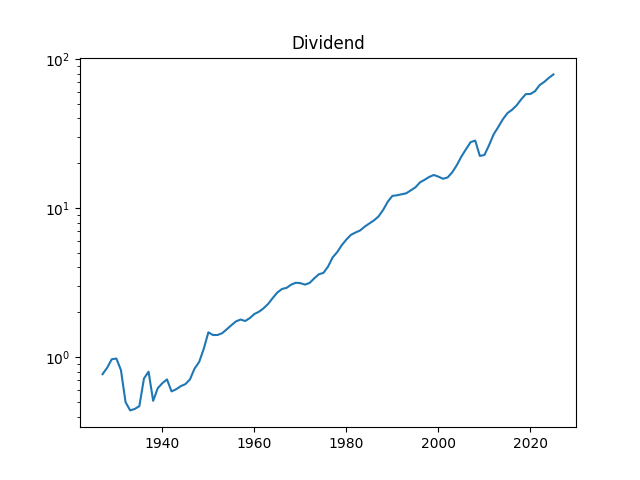
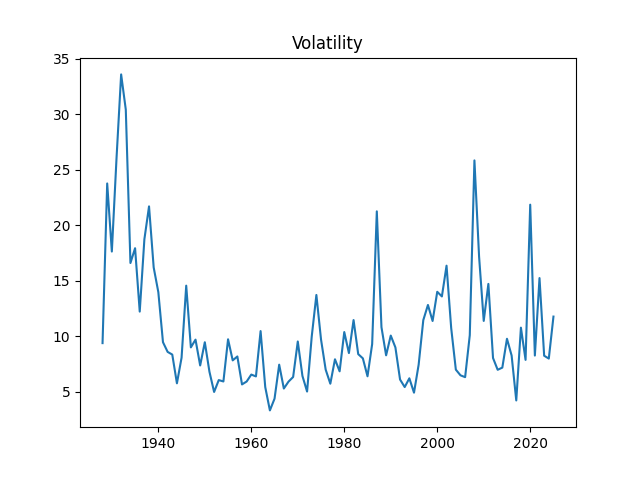
1. Data Updates. Annual volatility is computed as the empirical standard deviation of daily log changes multiplied by 1000 (for normalizing). The end-of-year price for S&P 500 in 2025 is also updated. We also add S&P 500 dividends for 2025. Now we have data on volatility for 1928-2025, on dividends for 1927-2025, and end-of-year level of S&P 500 for 1927-2025 too.
We added the dividend data for 1927 as well, to increase the number of data points. This is fine, since S&P 90 (a predecessor for S&P 500) was created in 1926, and the data is taken from Robert Shiller’s data library.
The volatility for 2025 is 11.77. This is higher than the long-term average 10.51, or the 2024 volatility, which is 7.98. See the original post with computations of Angel Piotrowski for 1928-2023 and its previous update for 2024.
Dividends for 2025 are 78.92, which is significantly higher than dividends for 2024, which are 74.83.
The S&P 500 increased a lot in 2025: End-of-year 2024 level is 5881.63, but end-of-year 2025 level is 6845.5.
We could not yet provide earnings for 2025, since we have earnings for 2025 Quarter 4 reported only on 2026 Quarter 1, which is still ongoing. We will provide them as soon as we can.
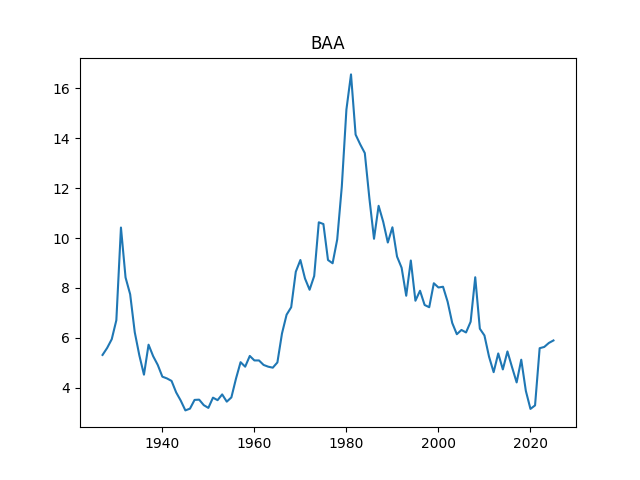
Finally, we added the BAA rate: December 2025 daily average. The BAA are lowest-rated investment-grade corporate bonds. The rate in December 2025 is 5.9, slightly higher than 5.8 for December 2024.
2. New Graphs. We graph the index, dividend, rates, and volatility.
Above, logarithmic plots of index levels and dividends for 1927-2025. Below, the annual volatility and December BAA rate.
The data are published on my web page: We created a new tab named Financial Data Library on my web page. Let us now apply
Let us replicate this post: Make stock returns IID Gaussian.
We have the following notation:
the S&P level at end-of-year
the dividend of S&P in year
December daily average BAA rate during year
annual realized volatility for the S&P for year
3. Total Returns. We continue this blog post. Compute total nominal geometric returns for the S&P 500: for year Below is the graph of returns 1928-2025.
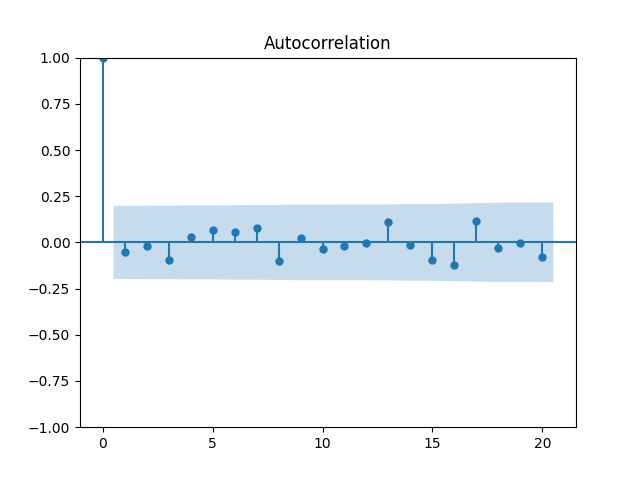
Now plot the autocorrelation function for these total returns And another autocorrelation function for their absolute values Both plots are below, and both are consistent with the white noise hypothesis. It is surprising that we, in fact, do not have to divide total returns by annual volatility to make it white noise.
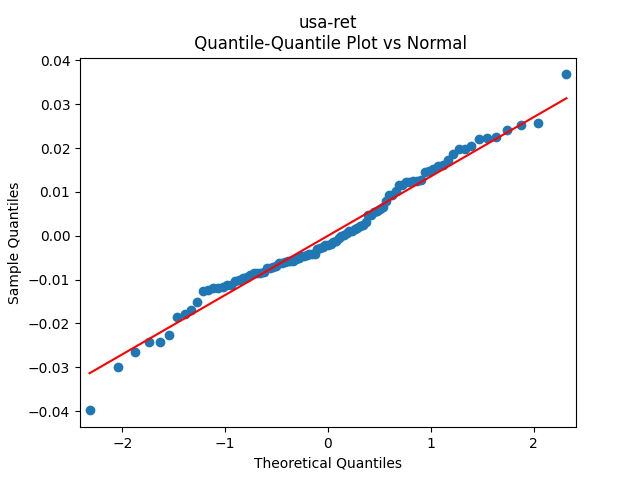
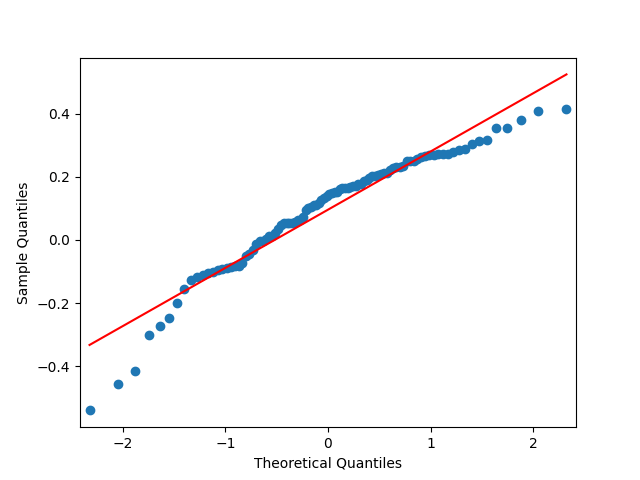
The quantile-quantile plot of these returns is shown as well. We see that the returns are not Gaussian. This is consistent with the normality testing. Shapiro-Wilk and Jarque-Bera tests give us and
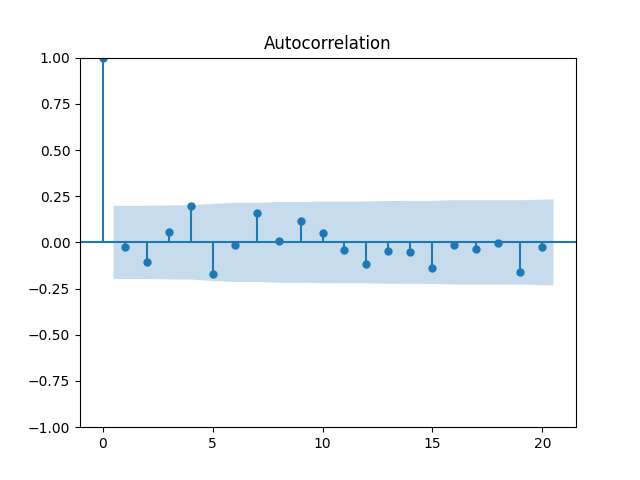
What if we do divide these total returns by annual volatility? We get Let us plot the autocorrelation function for and the autocorrelation function for
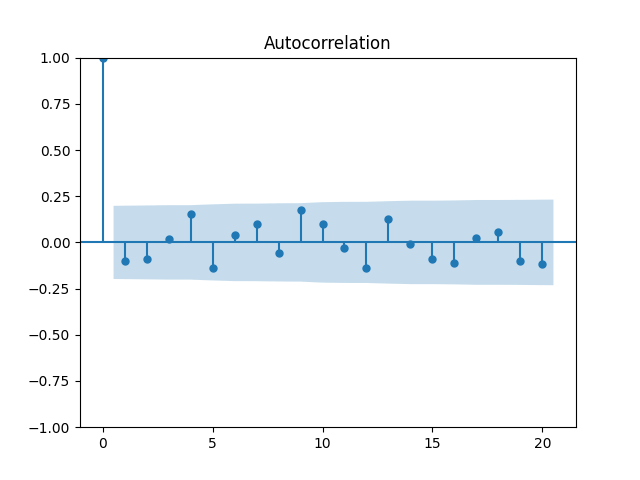
These are still consistent with white noise, although, in my view, the autocorrelation function values are greater. But the quantile-quantile plot versus the normal distribution is below. We get and for Shapiro-Wilk and Jarque-Bera normality tests.
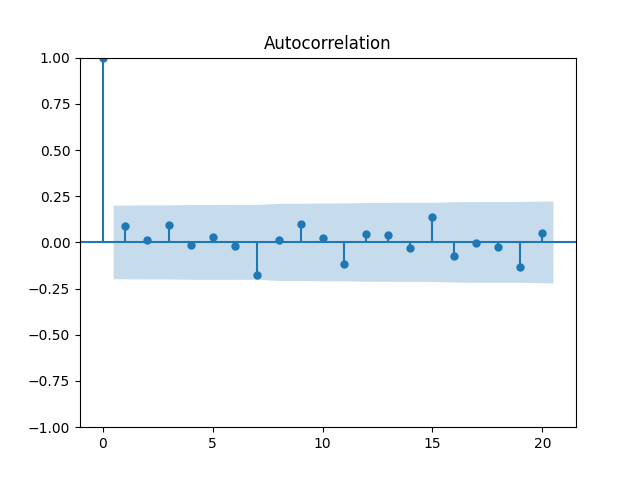
4. Volatility Autoregression. We continue this blog post. Let us now fit the auto-regression model for logarithm of volatility:
We fit and Also, plotting the autocorrelation function of and of we see:
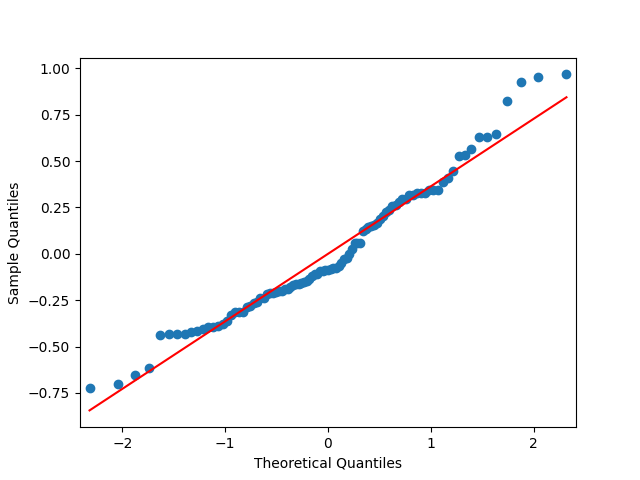
This is consistent with the assumption that are independent identically distributed. But it is more ambiguous to assume they are Gaussian, see the quantile-quantile plot below. The Shapiro-Wilk and Jarque-Bera tests give us and respectively.
5. Price Returns. These are computed as We continue this blog post. These contain only price changes, not dividends. The autocorrelation function for these values and their absolute values is plotted below.
Quite close to independent identically distributed! Next, the quantile-quantile plot versus the Gaussian distribution: This shows price returns are not Gaussian, similarly to total returns. This is confirmed by familiar Shapiro-Wilk and Jarque-Bera tests and
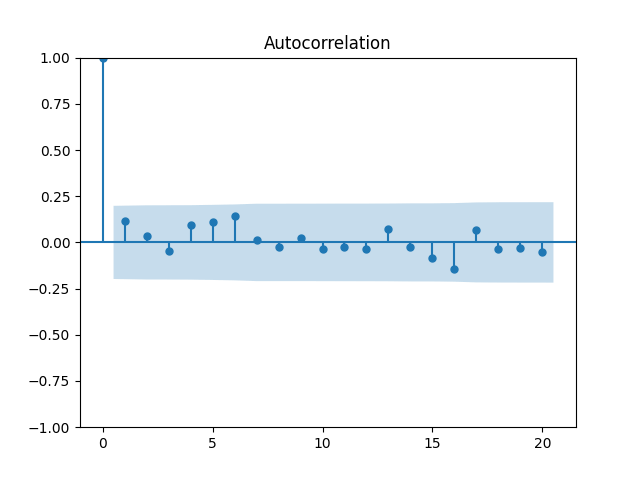
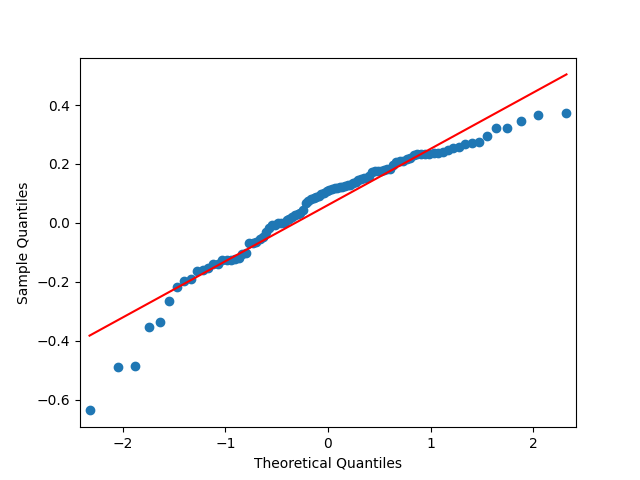
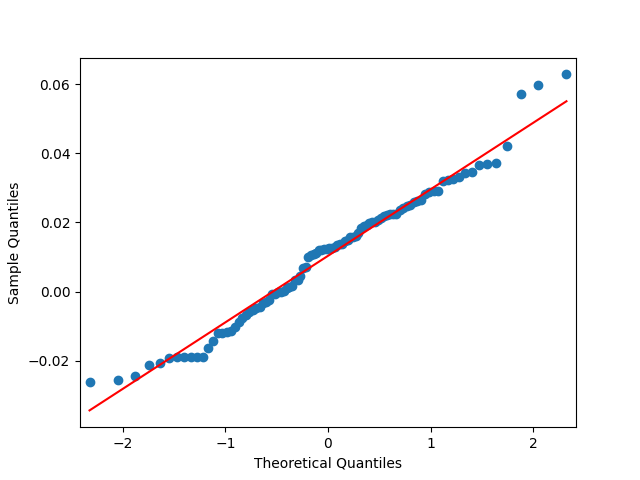
Let us divide price returns by volatility. Below we plot the autocorrelation function of and of and see that this is still consistent with being independent identically distributed. Only these values are slightly higher.
The Shapiro-Wilk and Jarque-Bera tests give us and respectively. See also the quantile-quantile plot. This is much closer to normal distribution.
Finally, let us plot price and total returns together. We see that, of course, total returns are greater than price returns.
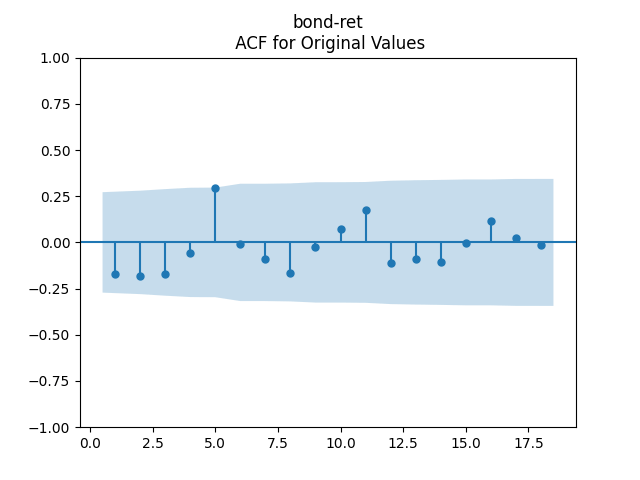
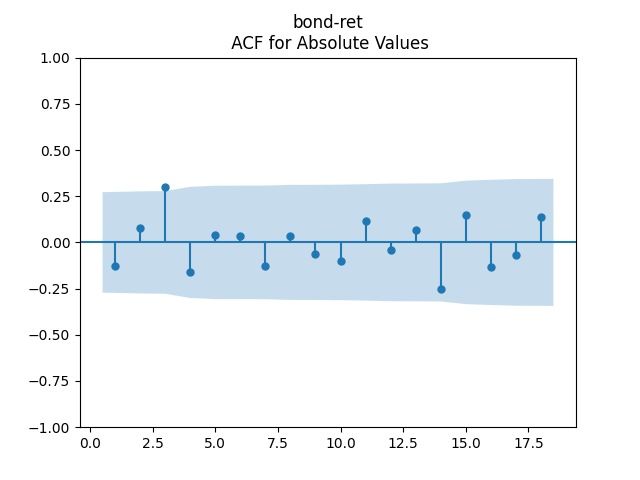
6. BAA Bond Rates. Continue this blog. We also fit a simple autoregression:
We get: and But the p-value for the null hypothesis when we have a random walk is so we fail to reject the random walk hypothesis. This is not acceptable from the financial point of view, since the random walk implies will go negative eventually. Also, consider the graphs of autocorrelation function for and for These are not independent identically distributed.
Both p-values for normality tests of innovations are less than 0.01%. The quantile-quantile plot is shown below for It is clear these are not Gaussian.
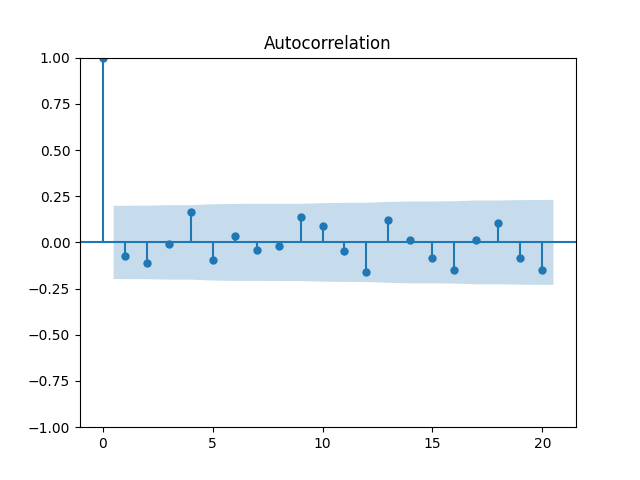
Instead, like for the volatility, let us take the logarithm:
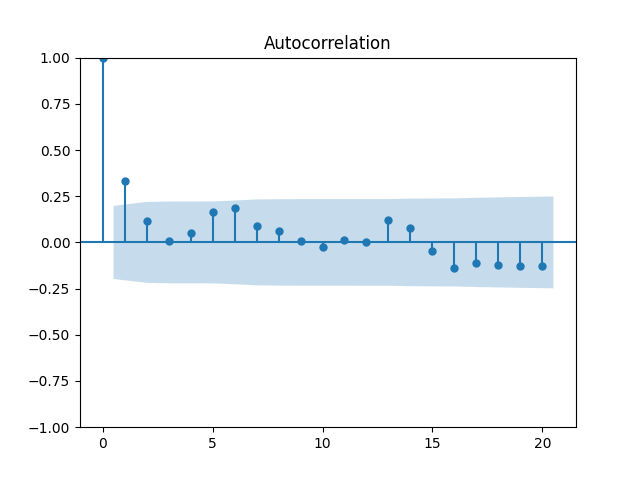
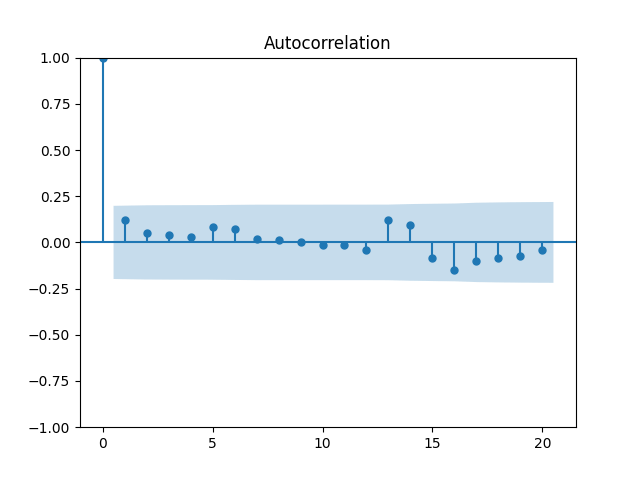
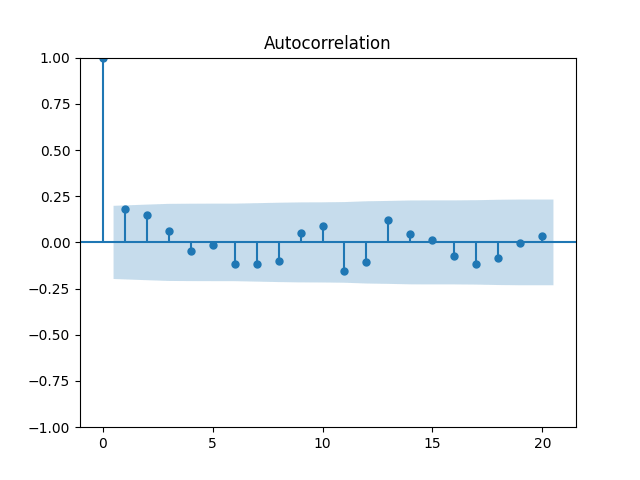
We get and with for the null hypothesis of random walk, which corresponds to Plot the autocorrelation function for and for below:
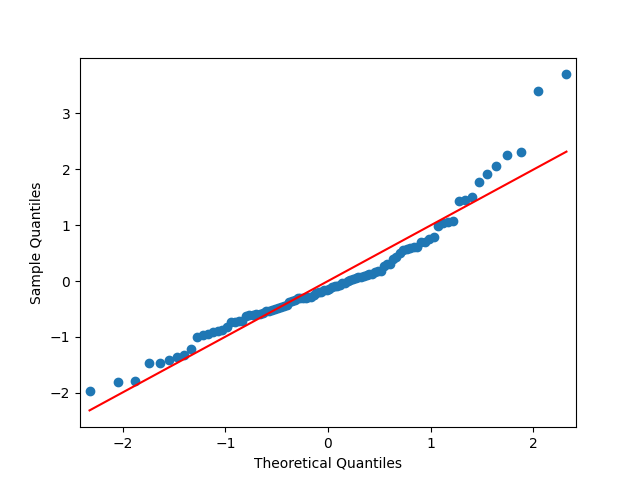
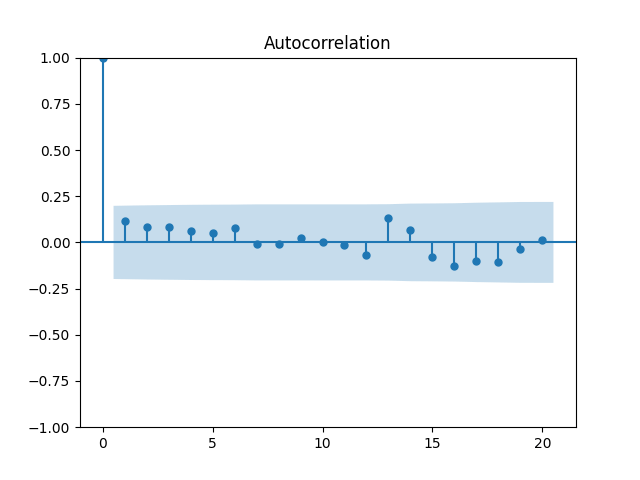
Let us modify this to try a random walk model: are they really independent identically distributed Gaussian? Below are the autocorrelation function plots for and for which show that these are independent identically distributed.
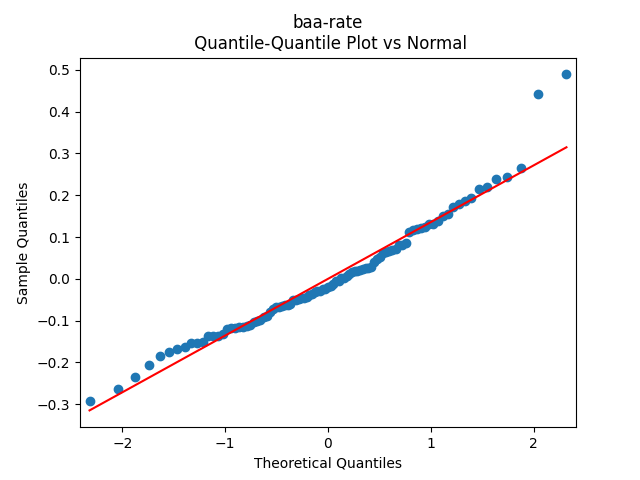
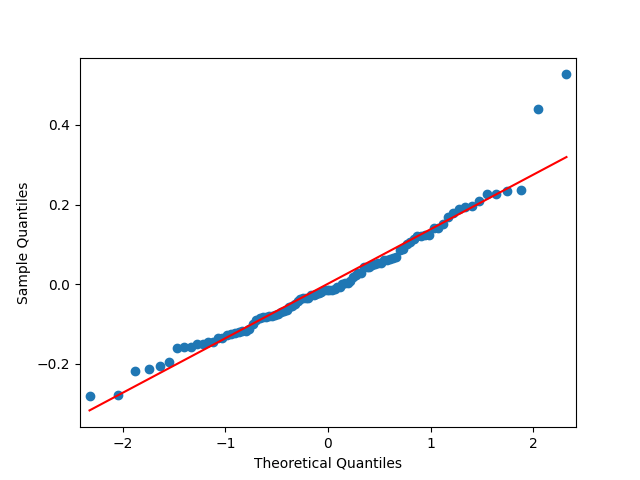
Next, the quantile-quantile plot versus the normal distribution is much closer to the straight line than before for other models of the BAA rate. This is confirmed that the Shapiro-Wilk and Jarque-Bera tests give us and which rejects the null hypothesis but are not as small as the previous ones.
Next, try to make these independent identically distributed but non-Gaussian terms Gaussian. We do the same as in sections 1 and 3: Divide the log rate change by volatility. We get Below are autocorrelation function plots for and for
The quantile-quantile plot below shows these are Gaussian terms, and the same is shown by the Shapiro-Wilk and Jarque-Bera tests with and This was done in the spirit of this blog post.
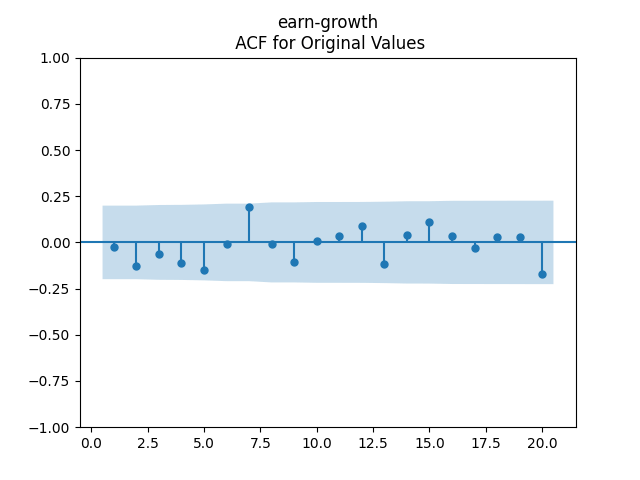
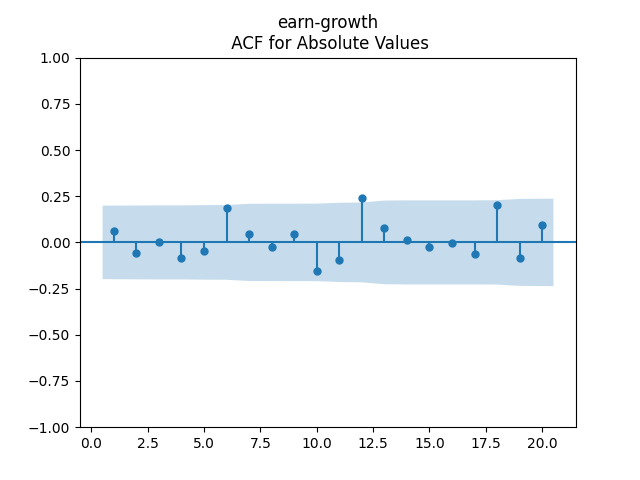
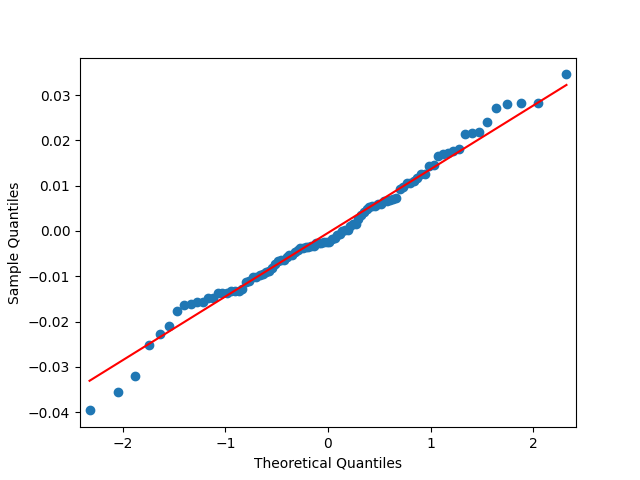
7. Dividend Growth is computed as We continue this blog post. See below the autocorrelation function plots for and for which show lag 1, also the quantile-quantile plot.
Define and analyze it as well. The data are closer to the Gaussian distribution, with and
See the plot of the dividend growth below. It is quite volatile but not as much as the stock returns. But we clearly see the persistence: It makes sense to model dividend growth or its normalized version as the simple autoregression. This is different from annual earnings growth, where dividing by volatility makes it independent identically distributed, see this blog post.
Let us try the simple autoregression for normalized annual dividend growth
We have and with Shapiro-Wilk and Jarque-Bera normality tests give us and See the graphs below, autocorrelation for autocorrelation for and the quantile-quantile plot for
Here we have independent identically distributed but not Gaussian residuals
8. Conclusion. Here, we found all time series Markov models for dividends, price and total returns, volatility, and the BAA rates. In the next post, we will discuss updates for the valuation measure based on one-year dividends instead of trailing 10-year earnings, and regression modeling using rate change and duration, continuing this post and this post.
In the repository https://github.com/asarantsev/advanced we added another page with advanced version of the simulator, where we can pick initial conditions for model factors:
S&P 500 Annual Volatility (VIX)
S&P 500 Bubble Valuation Measure
Moody’s BAA Bond Rate
Treasury 10Y – 3M Long-Short Bond Spread
We repainted the button Compute in orange. For the advanced option, we made the legend font and the web page font smaller. And we updated the default initial conditions for the main version of the simulator to make it for June 2025.
See the historical graphs of these four measures below. We can see their historical range. We included them in the HTML page for the advanced version of the simulator.
Below we see the autocorrelation function plots for original and absolute values, and the quantile-quantile plot versus the normal distribution, of residuals for each of the seven regressions. First, let us consider four factors: volatility, BAA rate, and spread (autoregressions for logarithms) and earnings growth divided by volatility (needed to compute the evolution of the bubble measure; here no regression).
Then consider regression residuals for total returns of three asset classes: S&P 500, International Stocks, USA Corporate Bonds.





















 to the equity premium (total returns minus risk-free returns)
to the equity premium (total returns minus risk-free returns) is usually very high. Of course, such factors might be not constant over time. For example, the
is usually very high. Of course, such factors might be not constant over time. For example, the  be the end-of-year (December daily average, more precisely) rate (assuming these three rates are the same). Then the price of a 10-year zero-coupon bond at end of year
be the end-of-year (December daily average, more precisely) rate (assuming these three rates are the same). Then the price of a 10-year zero-coupon bond at end of year  is
is  and it becomes a 9-year zero-coupon bond with rate
and it becomes a 9-year zero-coupon bond with rate  and the geometric returns are
and the geometric returns are 
 and
and  we model
we model  and
and  for Gaussian independent identically distributed
for Gaussian independent identically distributed 
 with
with  The regression which defines such measure is an autoregression of order 1 with a linear trend:
The regression which defines such measure is an autoregression of order 1 with a linear trend:  Its innovations
Its innovations  do not satisfy the assumptions 1-5 from the previous post. Therefore, we reject the regression as the model. But we accept this model:
do not satisfy the assumptions 1-5 from the previous post. Therefore, we reject the regression as the model. But we accept this model:
 The
The  is 11.77 and 10.51
is 11.77 and 10.51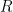 is 5.9 and 6.8
is 5.9 and 6.8 is 0.192 and 0.24
is 0.192 and 0.24 The values are
The values are  All coefficients are significantly different from zero. Also,
All coefficients are significantly different from zero. Also,  which is very high! Usually, annual stock returns are not very predictable.
which is very high! Usually, annual stock returns are not very predictable.  and all coefficients are significant except the valuation measure. So it is not needed, after all. Without the new valuation measure, the regression has
and all coefficients are significant except the valuation measure. So it is not needed, after all. Without the new valuation measure, the regression has  We do not need this!
We do not need this!  and we can treat them as multivariate Gaussian independent identically distributed with covariance matrix (times 10000):
and we can treat them as multivariate Gaussian independent identically distributed with covariance matrix (times 10000):  for each of the following 5 statistical tests:
for each of the following 5 statistical tests: is modeled as
is modeled as  for
for  which corresponds to domestic and international geometric stock returns. Also, a sub-model with
which corresponds to domestic and international geometric stock returns. Also, a sub-model with  (no duration) or
(no duration) or  (no volatility as an additive factor) or both.
(no volatility as an additive factor) or both.  and regress
and regress  or
or  We accept them but reject the augmented models (for both arithmetic and geometric adjusted returns): with factors
We accept them but reject the augmented models (for both arithmetic and geometric adjusted returns): with factors  (intercept) and
(intercept) and  (volatility as an additive factor).
(volatility as an additive factor). works.
works.  is accepted. But we reject the one with
is accepted. But we reject the one with  instead of
instead of 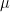 or with
or with  Models with
Models with  are rejected. These are stationary models.
are rejected. These are stationary models.  is also accepted, as well as an augmented model with volatility as an additive factor:
is also accepted, as well as an augmented model with volatility as an additive factor:  The models without logarithms or volatility or both are rejected. These are non-stationary models.
The models without logarithms or volatility or both are rejected. These are non-stationary models. for
for  for stock and bond returns. Next, AR(1) for log volatility and
for stock and bond returns. Next, AR(1) for log volatility and  for domestic and
for domestic and  for international stocks.
for international stocks. 


 (times 10000) is:
(times 10000) is: of regression residuals.
of regression residuals.  during year
during year  available 1970-2025.
available 1970-2025.  for the USA corporate bonds (measured by Bank of America Intercontinental Exchange total return index value, taken from
for the USA corporate bonds (measured by Bank of America Intercontinental Exchange total return index value, taken from  for year
for year  where
where  are innovation series. This is in line with our long-standing idea of dividing stock returns by volatility to make them closer to IID Gaussian. It works perfectly well here.
are innovation series. This is in line with our long-standing idea of dividing stock returns by volatility to make them closer to IID Gaussian. It works perfectly well here.  Note that this makes the rates non-stationary: More like a geometric random walk, except we have stochastic volatility here. This is one more remarkable example of how to use stock volatility for bonds, which we discussed earlier.
Note that this makes the rates non-stationary: More like a geometric random walk, except we have stochastic volatility here. This is one more remarkable example of how to use stock volatility for bonds, which we discussed earlier. 

 is IID Gaussian series with mean zero. This is confirmed by the tests and graphs above.
is IID Gaussian series with mean zero. This is confirmed by the tests and graphs above.  then the innovations are also IID Gaussian. This involves duration for stocks just like for bonds. The values of coefficients are significantly different from zero. Accept!
then the innovations are also IID Gaussian. This involves duration for stocks just like for bonds. The values of coefficients are significantly different from zero. Accept! and
and  has
has  for Student T-test. Accept!
for Student T-test. Accept! Here
Here  is different from zero, judging by the Student T-test. Accept!
is different from zero, judging by the Student T-test. Accept! but this violates normality of
but this violates normality of  Same would be true for the simple autoregression
Same would be true for the simple autoregression  Reject! Unfortunately, this means we must consider a non-stationary model.
Reject! Unfortunately, this means we must consider a non-stationary model.  But this would fail the IID assumption. Reject!
But this would fail the IID assumption. Reject! we replace de facto arithmetic returns with geometric returns, but in a modified way. The IID Gaussian assumption holds. Accept!
we replace de facto arithmetic returns with geometric returns, but in a modified way. The IID Gaussian assumption holds. Accept! and regress
and regress  versus the previous value
versus the previous value  and the time trend
and the time trend  This autoregression will also have residuals
This autoregression will also have residuals  Such residuals are tested and they do not pass our tests: They are not IID. Reject!
Such residuals are tested and they do not pass our tests: They are not IID. Reject!


 , we take FRED series BAMLCC0A0CMTRIV, last trading day of year 1972-2025. We start from
, we take FRED series BAMLCC0A0CMTRIV, last trading day of year 1972-2025. We start from  for the last trading day of 1972, and go on from there. This way we can compute log price returns for year
for the last trading day of 1972, and go on from there. This way we can compute log price returns for year 
 and at end of year
and at end of year  Assuming the price of this bond at end of year
Assuming the price of this bond at end of year  Then the coupon paid during year
Then the coupon paid during year  The wealth at end of year
The wealth at end of year  at end of year
at end of year 
 This gives us the formula for log price returns:
This gives us the formula for log price returns:
 are observed, we can compute
are observed, we can compute  If we fit this model, we can rewrite
If we fit this model, we can rewrite 
 can be regressed upon
can be regressed upon  We do not include an intercept into this regression, since this has the meaning of a discrete approximation of a derivative. The regression coefficient is 6.1053, and the residual analysis is done by the plots below. These are Gaussian but not quite independent identically distributed. This is confirmed by the p-values of Shapiro-Wilk and Jarque-Bera normality tests:
We do not include an intercept into this regression, since this has the meaning of a discrete approximation of a derivative. The regression coefficient is 6.1053, and the residual analysis is done by the plots below. These are Gaussian but not quite independent identically distributed. This is confirmed by the p-values of Shapiro-Wilk and Jarque-Bera normality tests:  and
and  And by the Ljung-Box test for 5 lags for original and absolute values of residuals, which give us
And by the Ljung-Box test for 5 lags for original and absolute values of residuals, which give us  and
and 
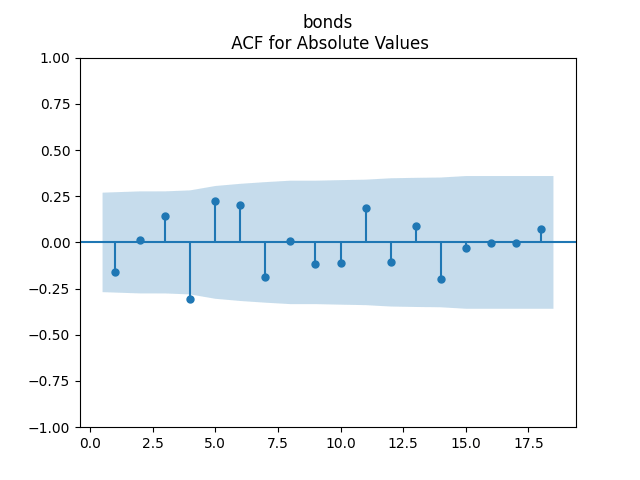
 This is equivalent to assuming that the residuals are heteroscedastic: These are white noise multiplied by
This is equivalent to assuming that the residuals are heteroscedastic: These are white noise multiplied by  for Shapiro-Wilk normality test,
for Shapiro-Wilk normality test,  for Jarque-Bera normality test. Also, the Ljung-Box test for the first 5 lags of original residuals has
for Jarque-Bera normality test. Also, the Ljung-Box test for the first 5 lags of original residuals has  and for absolute residuals has
and for absolute residuals has  Finally, see the graphs for residuals below.
Finally, see the graphs for residuals below. 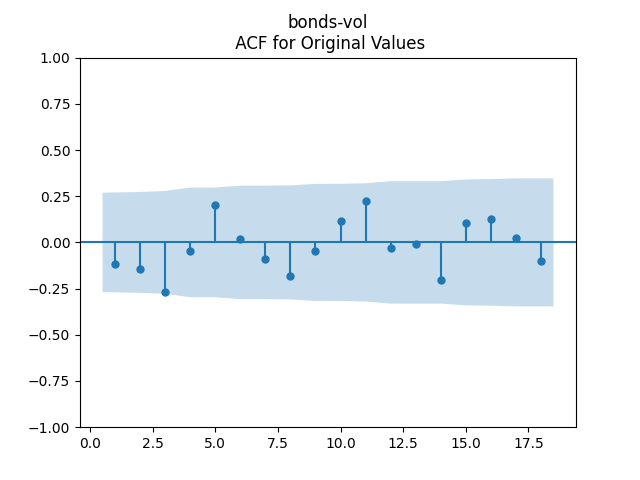
 where
where  What is more, this is better than previous models:
What is more, this is better than previous models: and
and 
 as a simple autoregression of order 1 with trend:
as a simple autoregression of order 1 with trend:  where
where 
 We fit
We fit  The autoregression becomes the random walk (there is no mean-reversion) if
The autoregression becomes the random walk (there is no mean-reversion) if  but this hypothesis has
but this hypothesis has  which is very low. Next, the trend coefficient is zero if
which is very low. Next, the trend coefficient is zero if  which has
which has 
 and compute the valuation measure
and compute the valuation measure 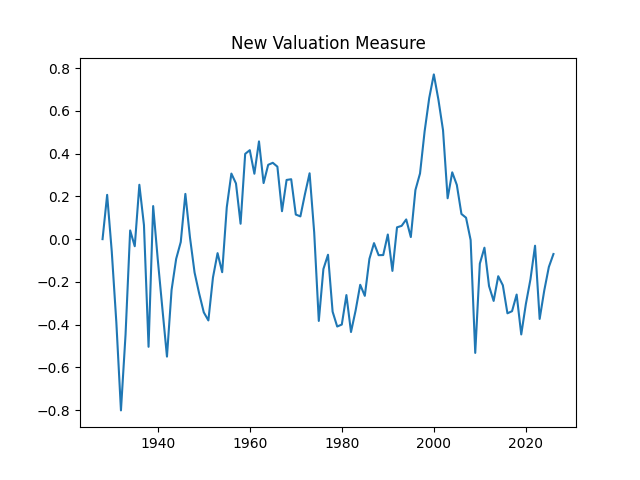
 as well as the quantile-quantile plot for
as well as the quantile-quantile plot for  The Shapiro-Wilk and the Jarque-Bera test give us
The Shapiro-Wilk and the Jarque-Bera test give us  and
and 
 as yet another autoregression
as yet another autoregression as follows:
as follows:
 Also the p-value for hypothesis
Also the p-value for hypothesis  is
is  The plots for residuals
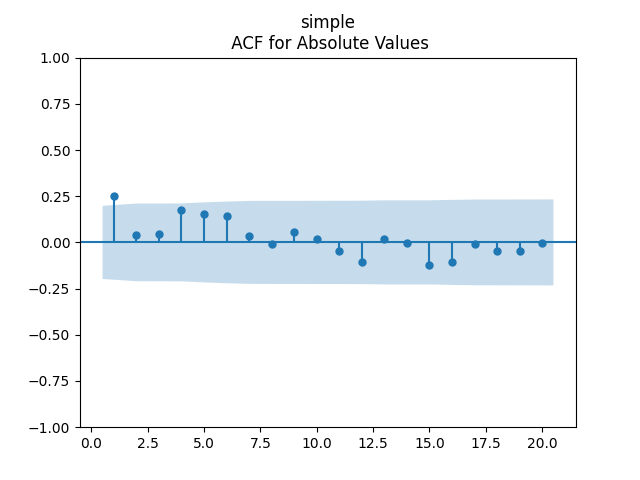
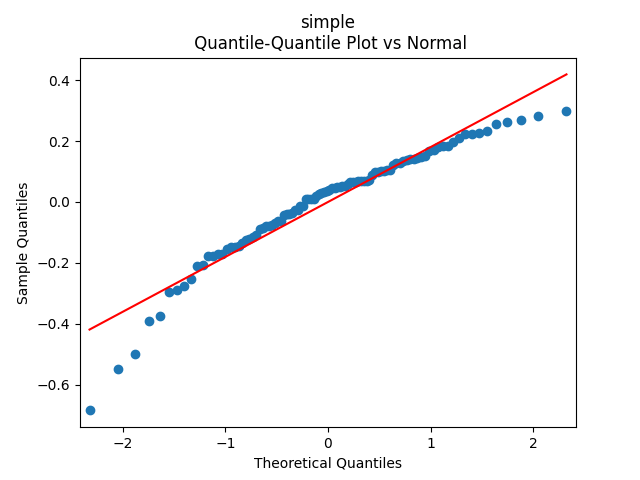
The plots for residuals  are below. This is independent identically distributed but not normal. Same is confirmed by the two normality tests, which give us extremely low p-values.
are below. This is independent identically distributed but not normal. Same is confirmed by the two normality tests, which give us extremely low p-values.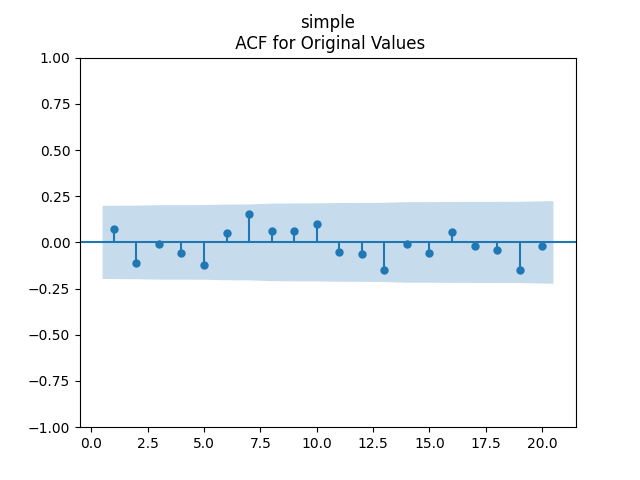
 regressed upon last year’s new valuation measure
regressed upon last year’s new valuation measure  as yet another autoregression
as yet another autoregression from the definition of the new valuation measure; and this does not have any new innovations. We modeled
from the definition of the new valuation measure; and this does not have any new innovations. We modeled  separately.
separately. 
 The p-values are all
The p-values are all  or less. The normality tests for innovations
or less. The normality tests for innovations  can be modeled as independent identically distributed Gaussian, therefore; see the three plots below.
can be modeled as independent identically distributed Gaussian, therefore; see the three plots below.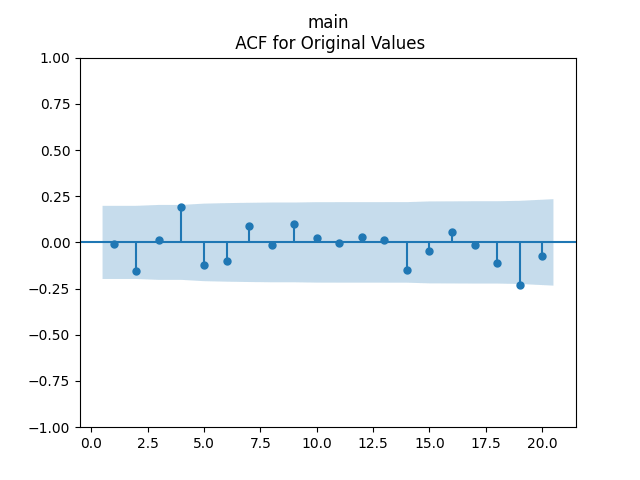
 in our time series models. Here
in our time series models. Here  The two other time series: the valuation measure
The two other time series: the valuation measure 
 and the autocorrelation function and quantile-quantile plots for residuals
and the autocorrelation function and quantile-quantile plots for residuals  shows this is not independent identically distributed and not Gaussian, see below.
shows this is not independent identically distributed and not Gaussian, see below.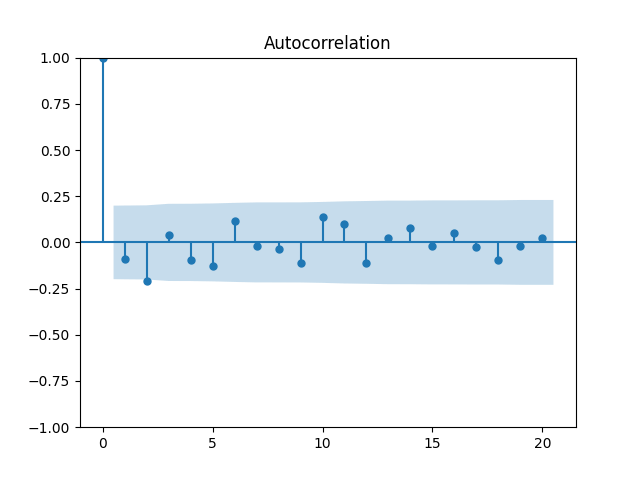
 instead of
instead of  This means using rate itself instead of rate change as a factor. Or normalize this rate by volatility:
This means using rate itself instead of rate change as a factor. Or normalize this rate by volatility:  In each case, still we have these plots as above for regression residuals.
In each case, still we have these plots as above for regression residuals. 
 with p-values 8.6% for valuation coefficient zero and less than 0.1% for intercept and duration. Also, the residuals are Gaussian, with Shapiro-Wilk and Jarque-Bera normality tests giving us
with p-values 8.6% for valuation coefficient zero and less than 0.1% for intercept and duration. Also, the residuals are Gaussian, with Shapiro-Wilk and Jarque-Bera normality tests giving us  and
and  But not independent identically distributed. See the three graphs below.
But not independent identically distributed. See the three graphs below. 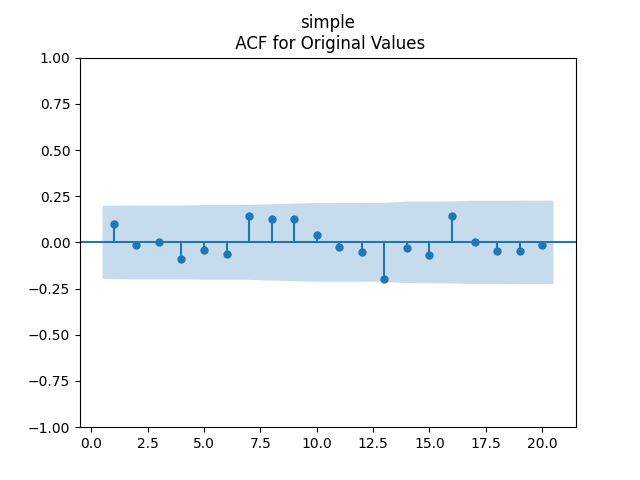
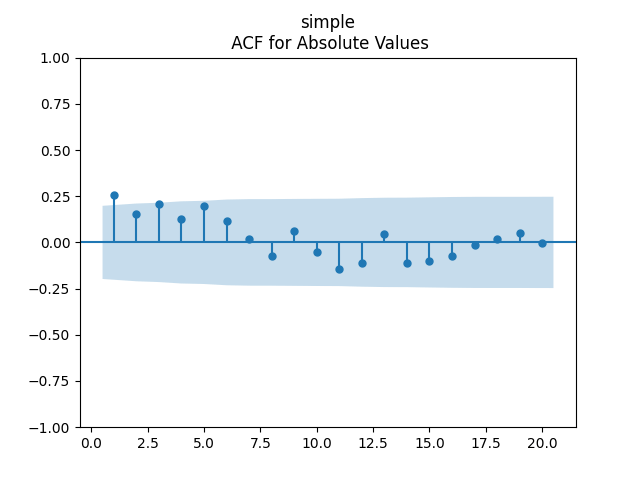

 with p-values 0.4% for valuation coefficient zero and 0.1% or less for others. Also, the residuals are Gaussian, with Shapiro-Wilk and Jarque-Bera normality tests giving us
with p-values 0.4% for valuation coefficient zero and 0.1% or less for others. Also, the residuals are Gaussian, with Shapiro-Wilk and Jarque-Bera normality tests giving us  and
and  Finally, looking at autocorrelation function plots for
Finally, looking at autocorrelation function plots for  we see that residuals are independent identically distributed Gaussian.
we see that residuals are independent identically distributed Gaussian.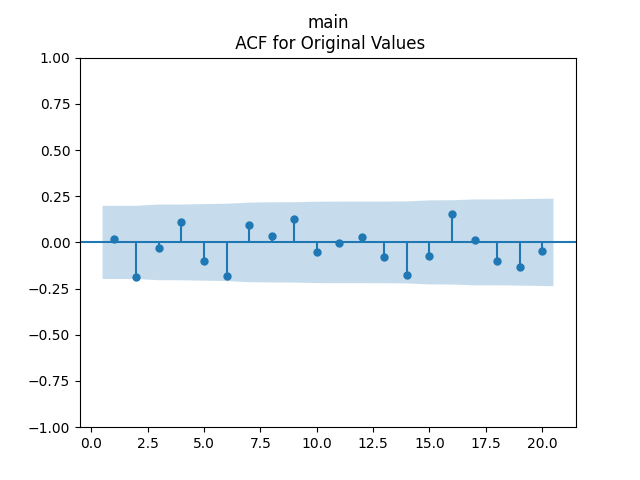
 for year
for year 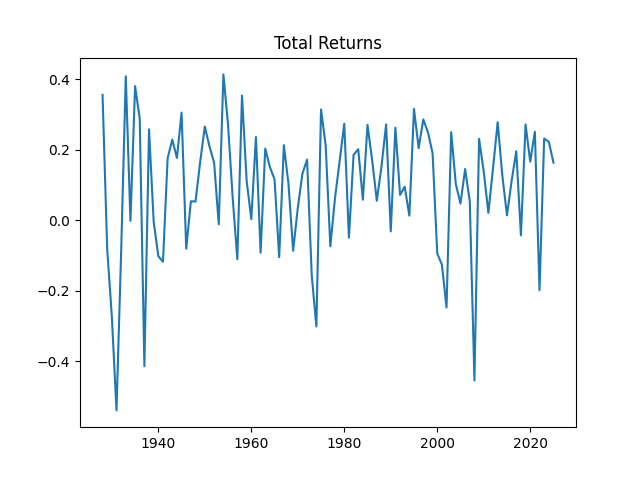
 And another autocorrelation function for their absolute values
And another autocorrelation function for their absolute values  Both plots are below, and both are consistent with the white noise hypothesis. It is surprising that we, in fact, do not have to divide total returns by annual volatility to make it white noise.
Both plots are below, and both are consistent with the white noise hypothesis. It is surprising that we, in fact, do not have to divide total returns by annual volatility to make it white noise. 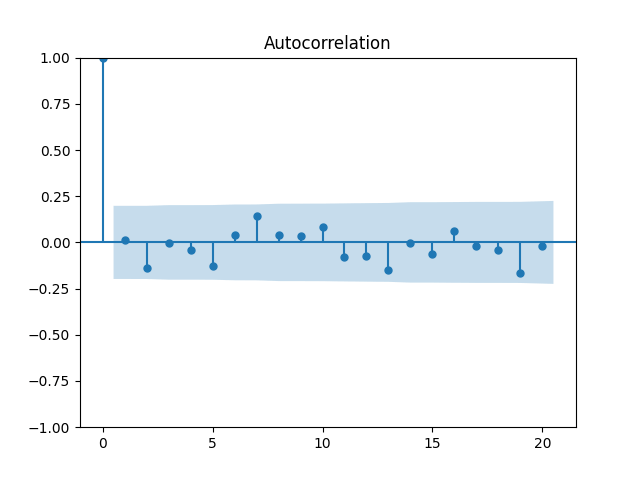
 and
and 
 Let us plot the autocorrelation function for
Let us plot the autocorrelation function for 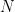 and the autocorrelation function for
and the autocorrelation function for 
 for Shapiro-Wilk and Jarque-Bera normality tests.
for Shapiro-Wilk and Jarque-Bera normality tests. 
 and
and  Also, plotting the autocorrelation function of
Also, plotting the autocorrelation function of 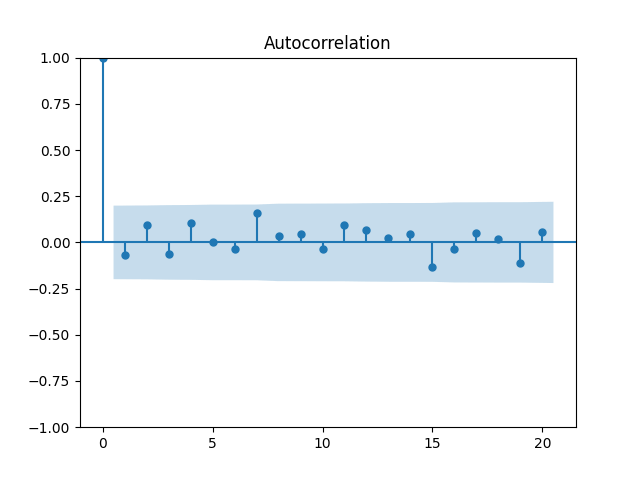
 and
and  respectively.
respectively.  We continue
We continue 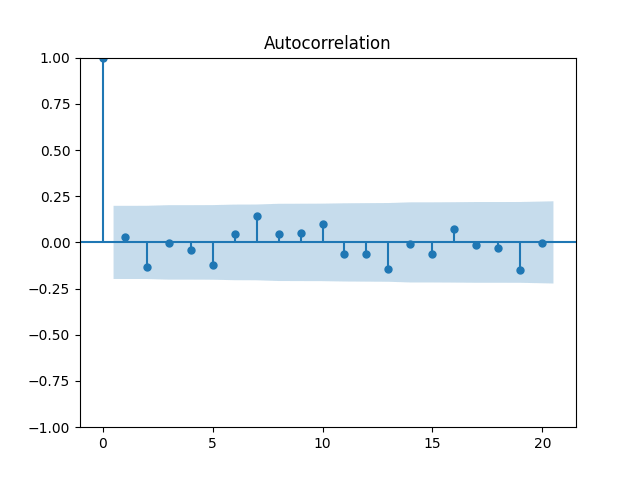
 and
and 
 and of
and of  and see that this is still consistent with being independent identically distributed. Only these values are slightly higher.
and see that this is still consistent with being independent identically distributed. Only these values are slightly higher. 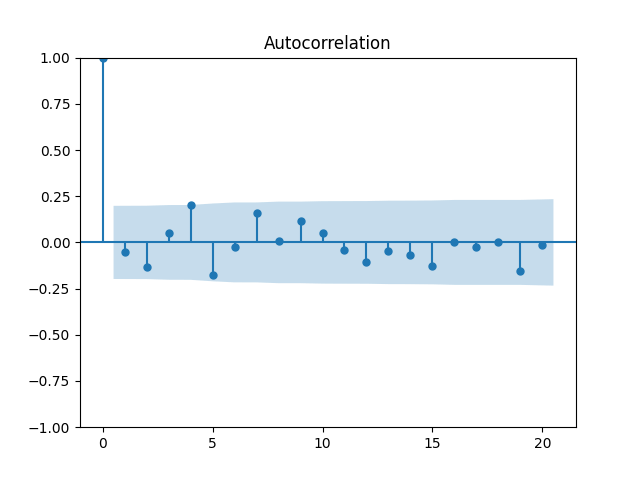
 and
and  respectively. See also the quantile-quantile plot. This is much closer to normal distribution.
respectively. See also the quantile-quantile plot. This is much closer to normal distribution. 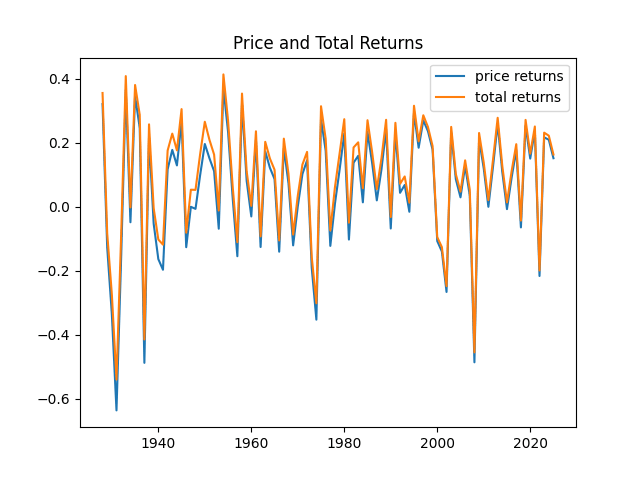

 and
and  But the p-value for the null hypothesis when we have a random walk is
But the p-value for the null hypothesis when we have a random walk is  so we fail to reject the random walk hypothesis. This is not acceptable from the financial point of view, since the random walk implies
so we fail to reject the random walk hypothesis. This is not acceptable from the financial point of view, since the random walk implies  These are not independent identically distributed.
These are not independent identically distributed.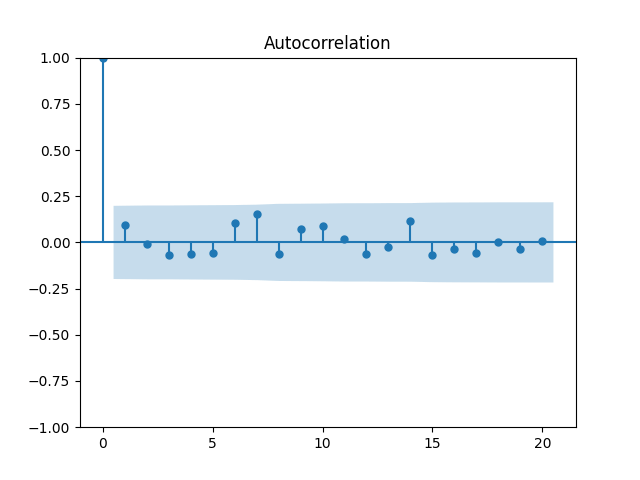

 and
and  with
with  for the null hypothesis of random walk, which corresponds to
for the null hypothesis of random walk, which corresponds to  Plot the autocorrelation function for
Plot the autocorrelation function for 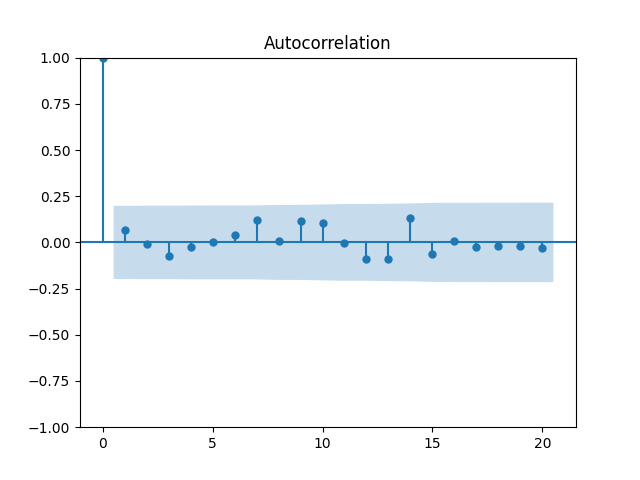
 are they really independent identically distributed Gaussian? Below are the autocorrelation function plots for
are they really independent identically distributed Gaussian? Below are the autocorrelation function plots for  and for
and for  which show that these are independent identically distributed.
which show that these are independent identically distributed.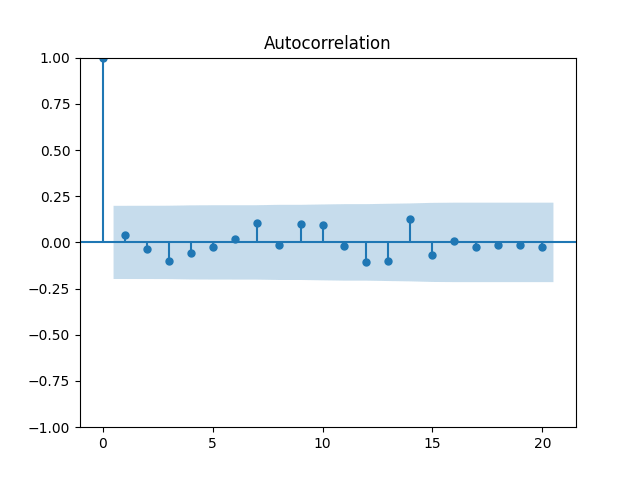
 and
and  which rejects the null hypothesis but are not as small as the previous ones.
which rejects the null hypothesis but are not as small as the previous ones.  Below are autocorrelation function plots for
Below are autocorrelation function plots for 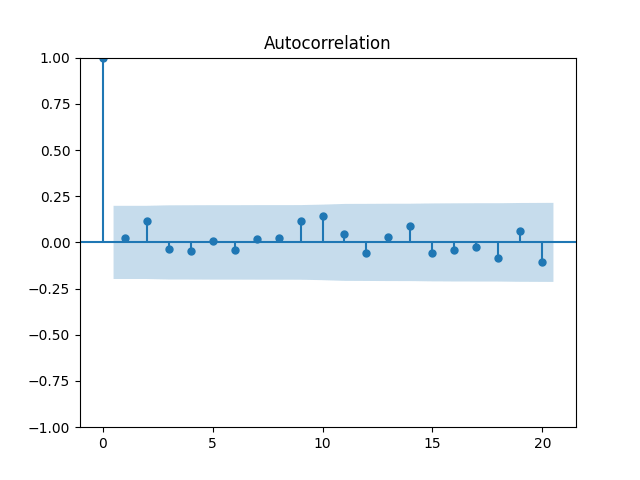
 and
and  This was done in the spirit of
This was done in the spirit of  We continue
We continue  which show lag 1, also the quantile-quantile plot.
which show lag 1, also the quantile-quantile plot.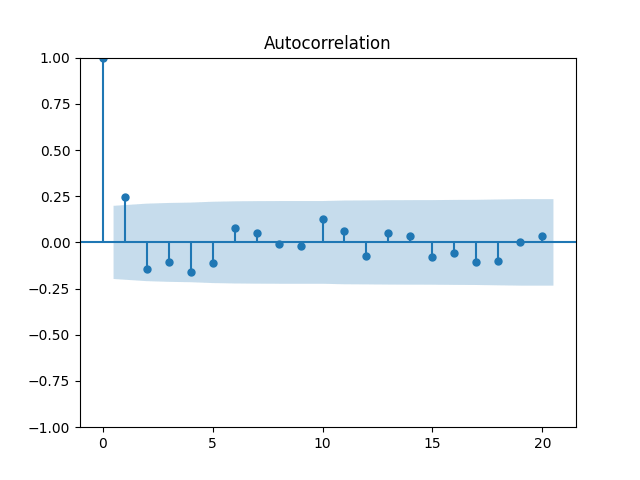
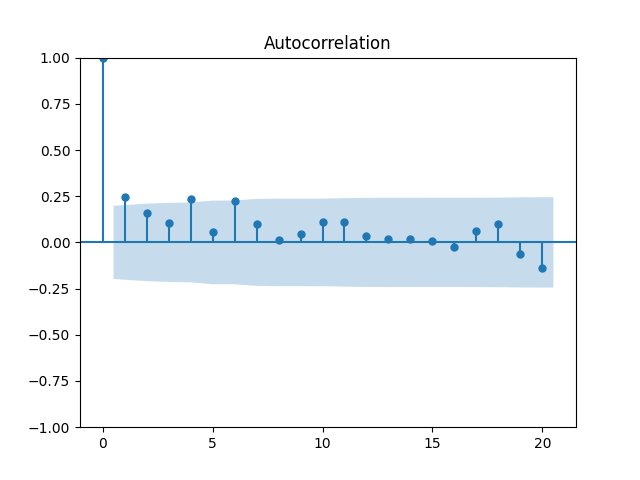
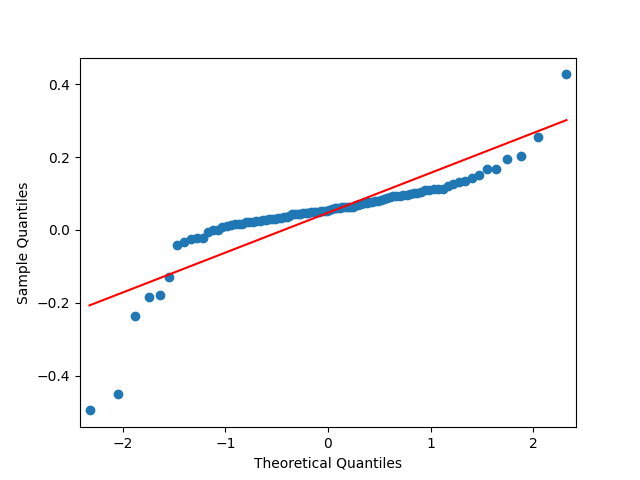
 and analyze it as well. The data are closer to the Gaussian distribution, with
and analyze it as well. The data are closer to the Gaussian distribution, with  and
and 
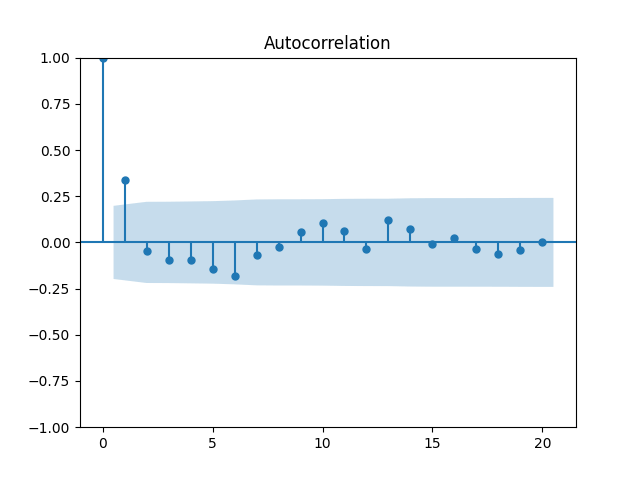
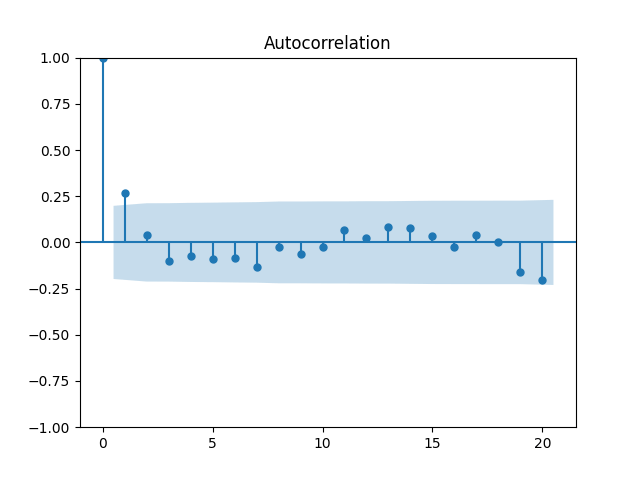
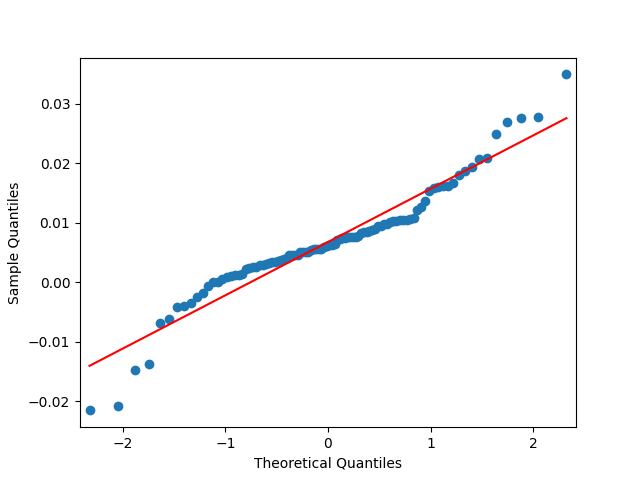
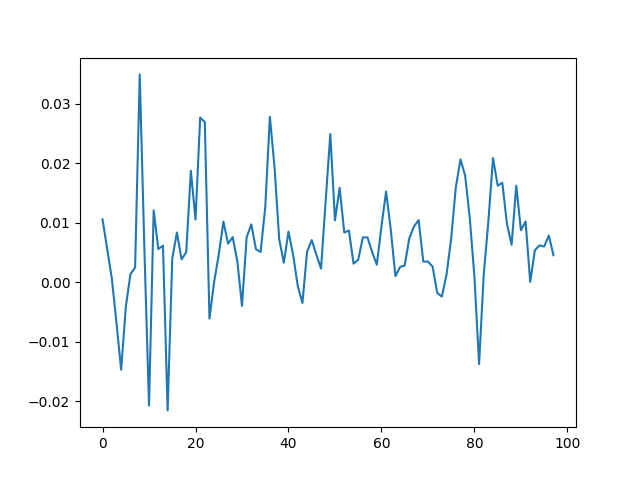


 and
and  with
with  Shapiro-Wilk and Jarque-Bera normality tests give us
Shapiro-Wilk and Jarque-Bera normality tests give us  and
and  See the graphs below, autocorrelation for
See the graphs below, autocorrelation for  autocorrelation for
autocorrelation for  and the quantile-quantile plot for
and the quantile-quantile plot for